Introduction to Exploratory and Confirmatory Factor Analysis (Using R)
Princeton University
4/11/23
How does it work?
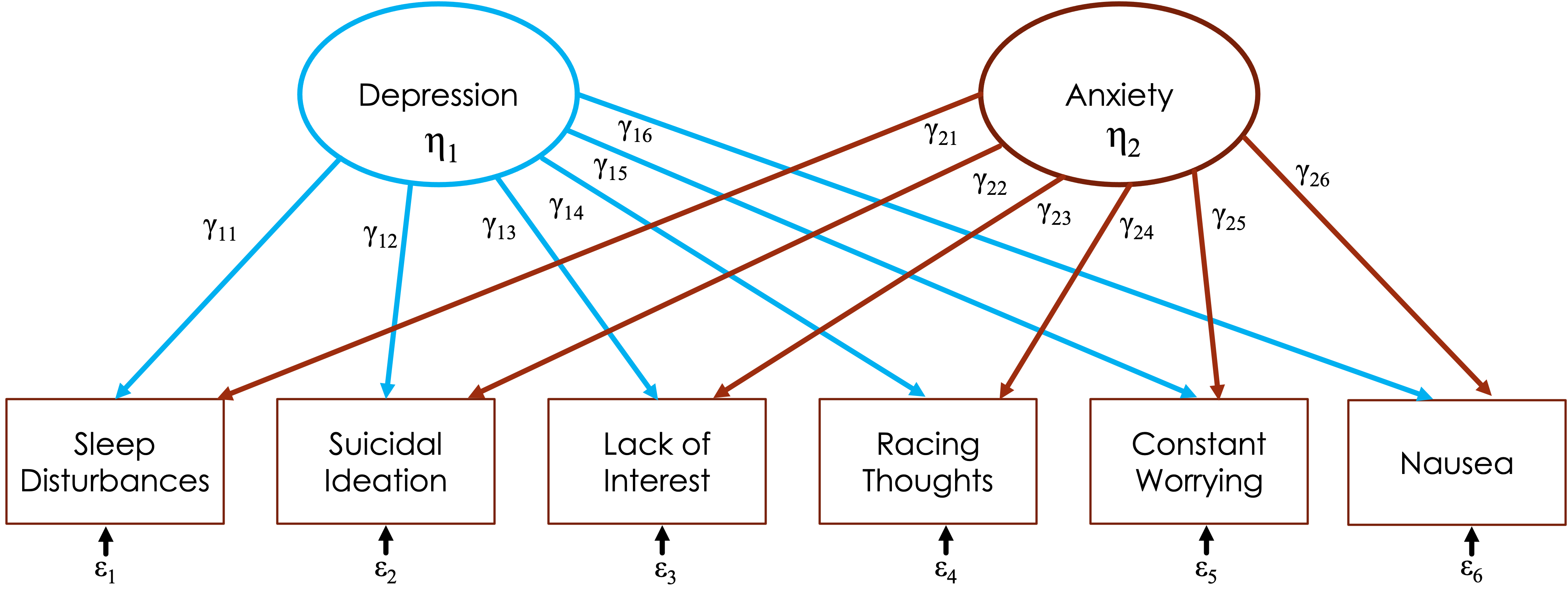
Let’s say we have 6 items in a scale:
Sleep disturbances (insomnia/hypersomnia)
Suicidal ideation
Lack of interest in normally engaging activities
Racing thoughts
Constant worrying
Nausea
Some of these could cross-load
FA considers this and items load on all factors
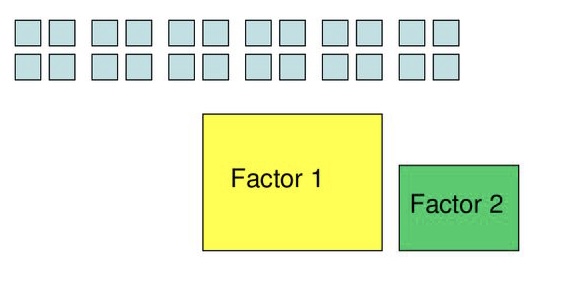
Uses
Simplify data
- 6 variables to 2 variables
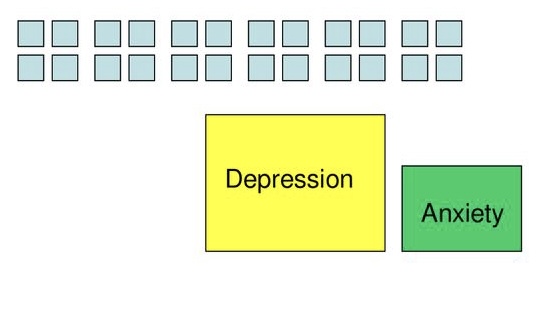
Uses
Identify underlying constructs
- Depression and anxiety
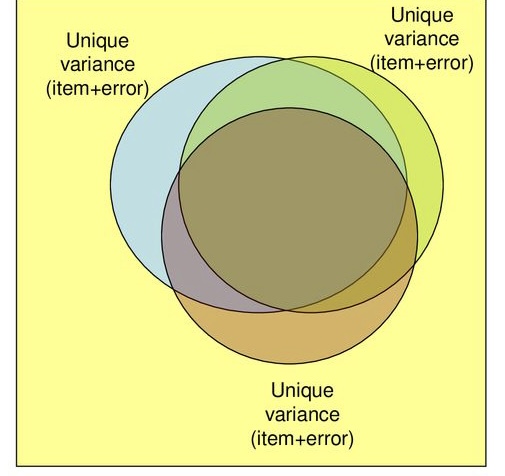
Partitioning Variance
- Variance common to other variables
- Communality \(h^2\): proportion of each variable’s/item’s variance that can be explained by the factors
- How much an item is related to other items in the analysis
- Communality \(h^2\): proportion of each variable’s/item’s variance that can be explained by the factors
- Variance specific to that variable
- Random measurement error
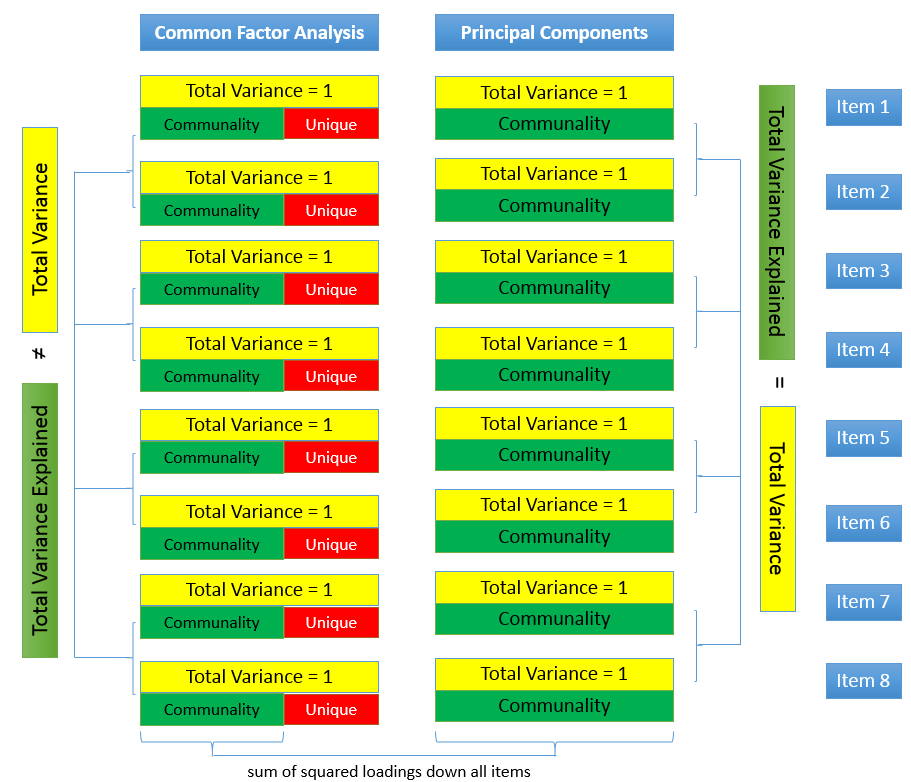
Common factor analysis
Common factor analysis
- Attempts to achieve parsimony (data reduction) by:
- Explaining the *maximum amount of common variance* in a correlation matrix
- Using the *smallest* number of explanatory constructs (factors)
- Explaining the *maximum amount of common variance* in a correlation matrix
- Attempts to achieve parsimony (data reduction) by:
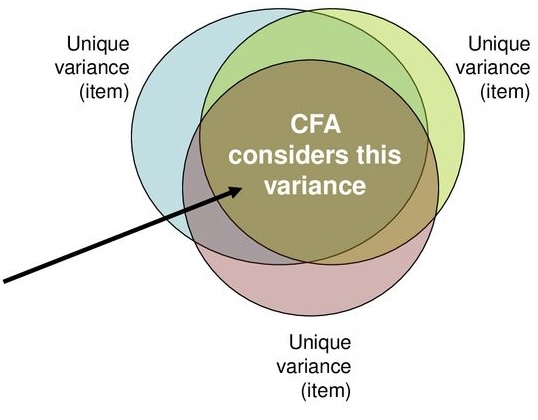
Common factor analysis
Common factor analysis
Common factor analysis
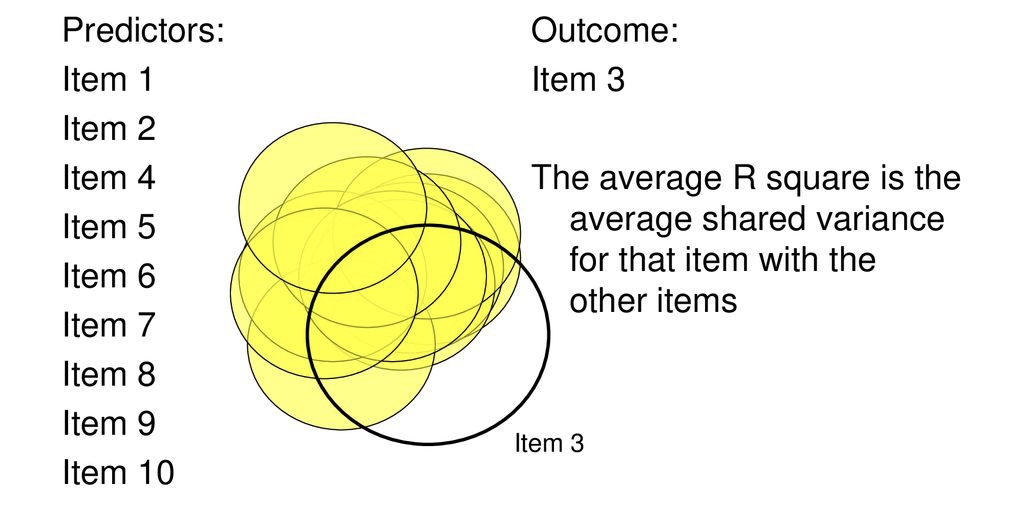
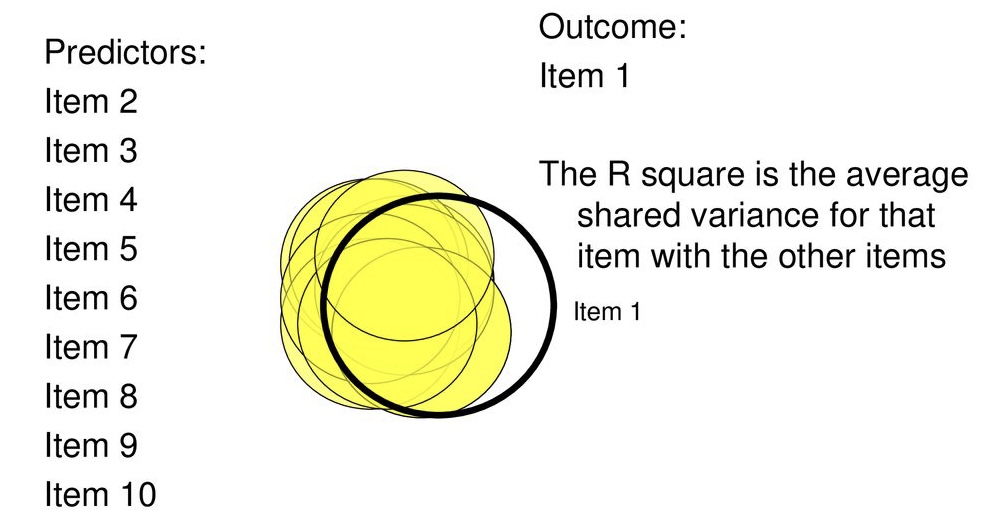
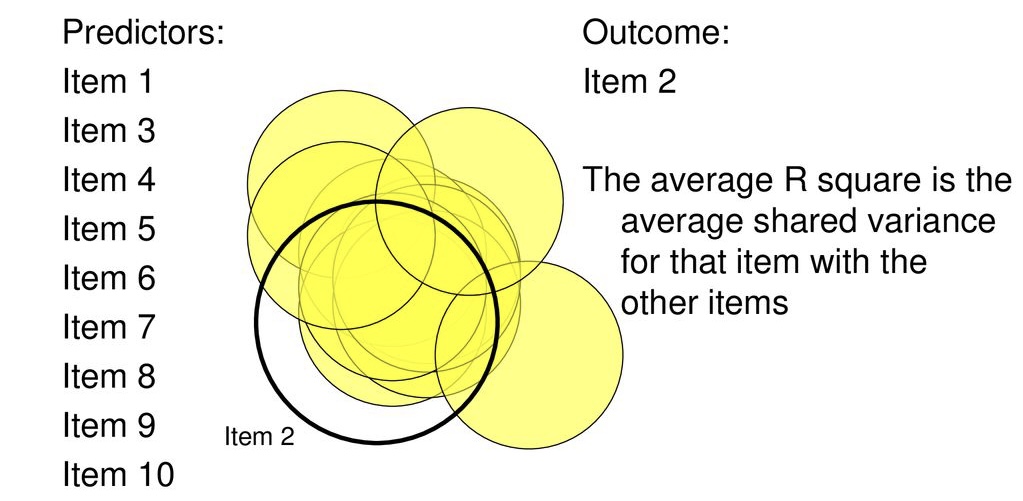
PCA
Assumption: Components that explain the most total variance
Goal: Find fewest components that account for the relationships among variables
Big 5
Big Five Personality Traits

Data visualization
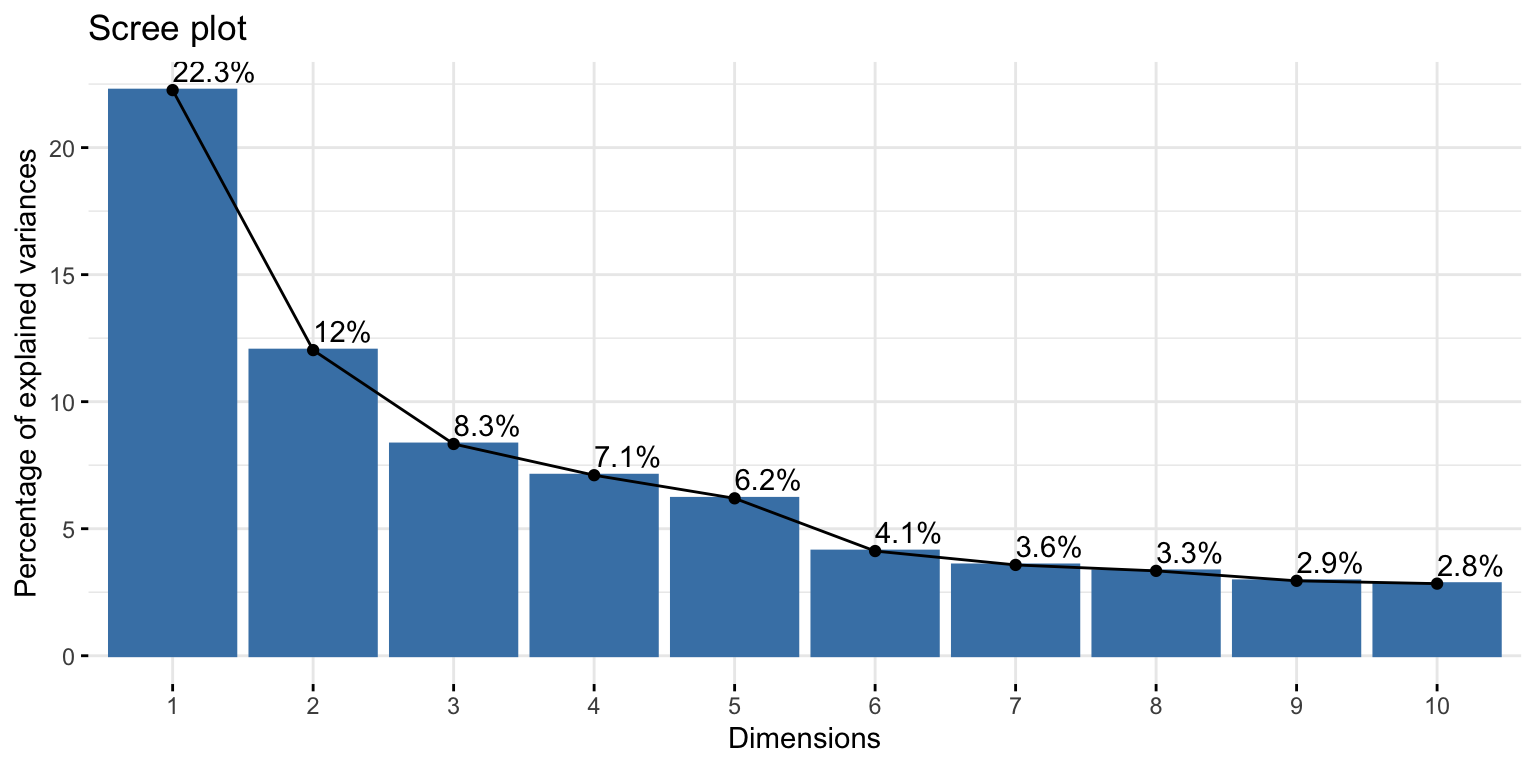
Fitting factor model: # of factors
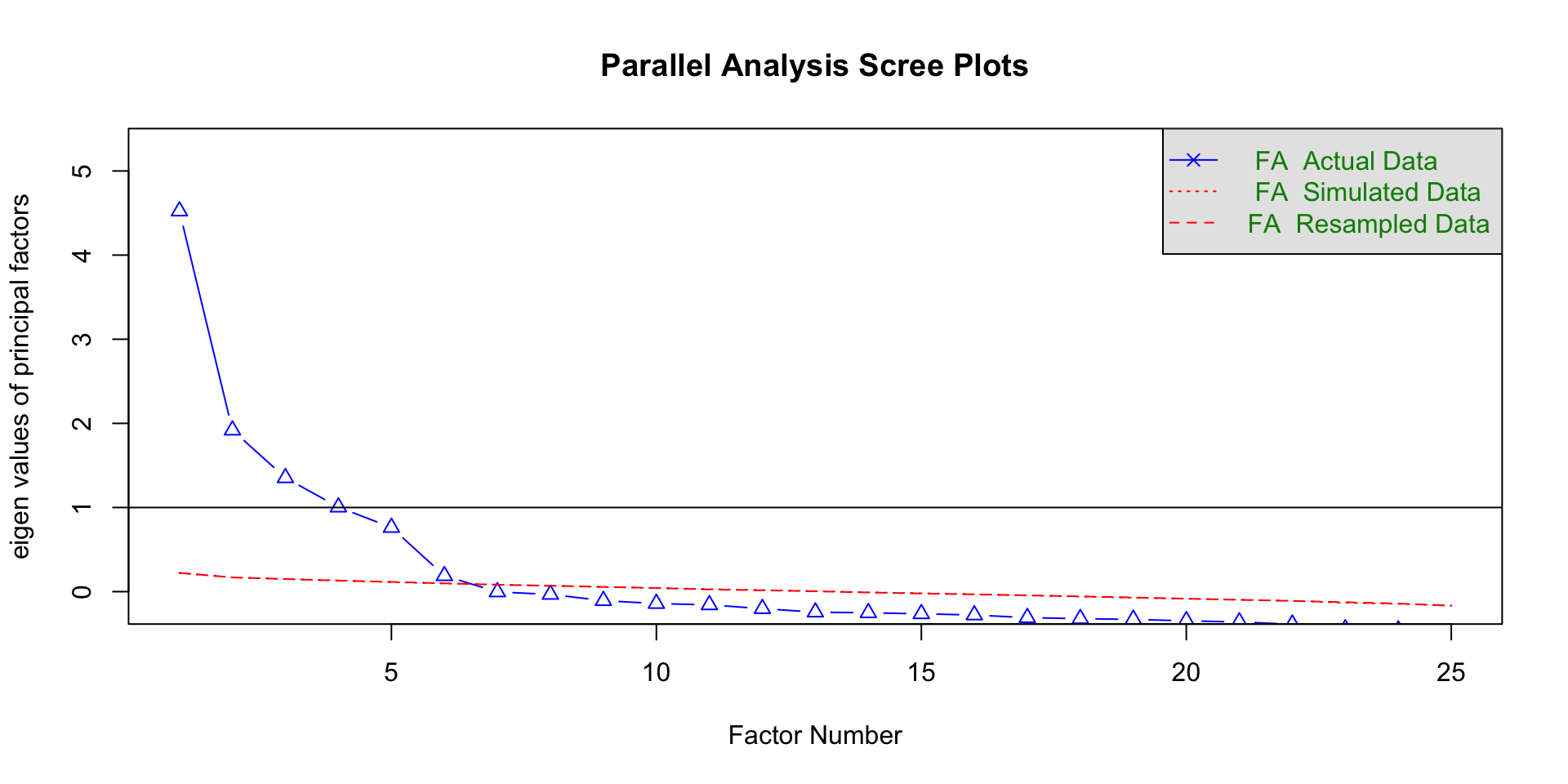
Scree plot
A plot of the Eigenvalues in order from largest to smallest
Look for the elbow (shared variability starting to level off)
- Above the elbow is how many components you want
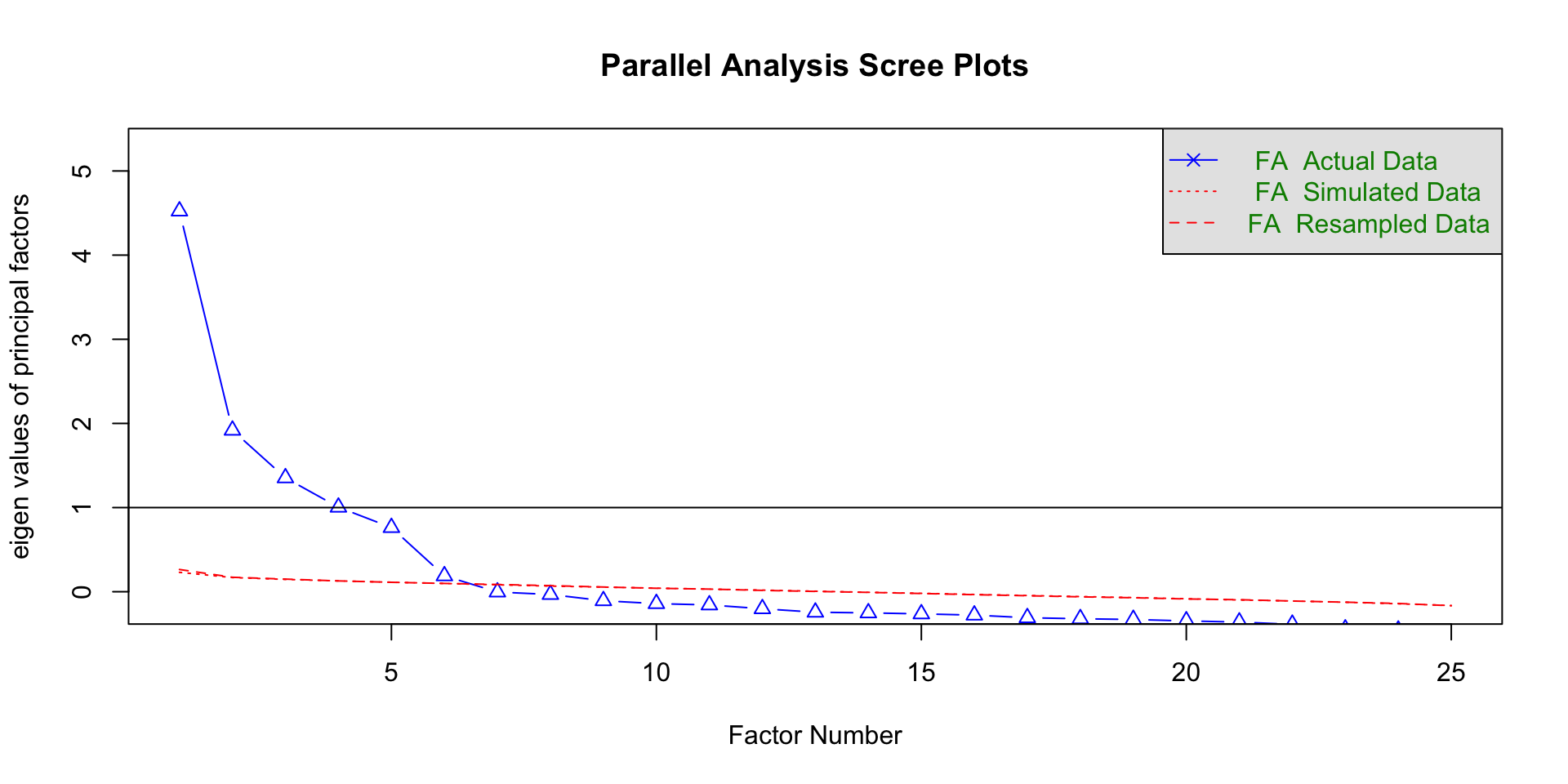
Fitting factor model: # of factors
Parallel analysis
Run simulations pulling eigenvalues from randomly generated datasets
If eigenvalues > eigenvalues from random datasets more likely to represent meaningful patterns in the data
More objective and reliable
Method agreement procedure
Uses many methods to determine how many factor you should get
- This is the approach I would use
Extracting factor loadings
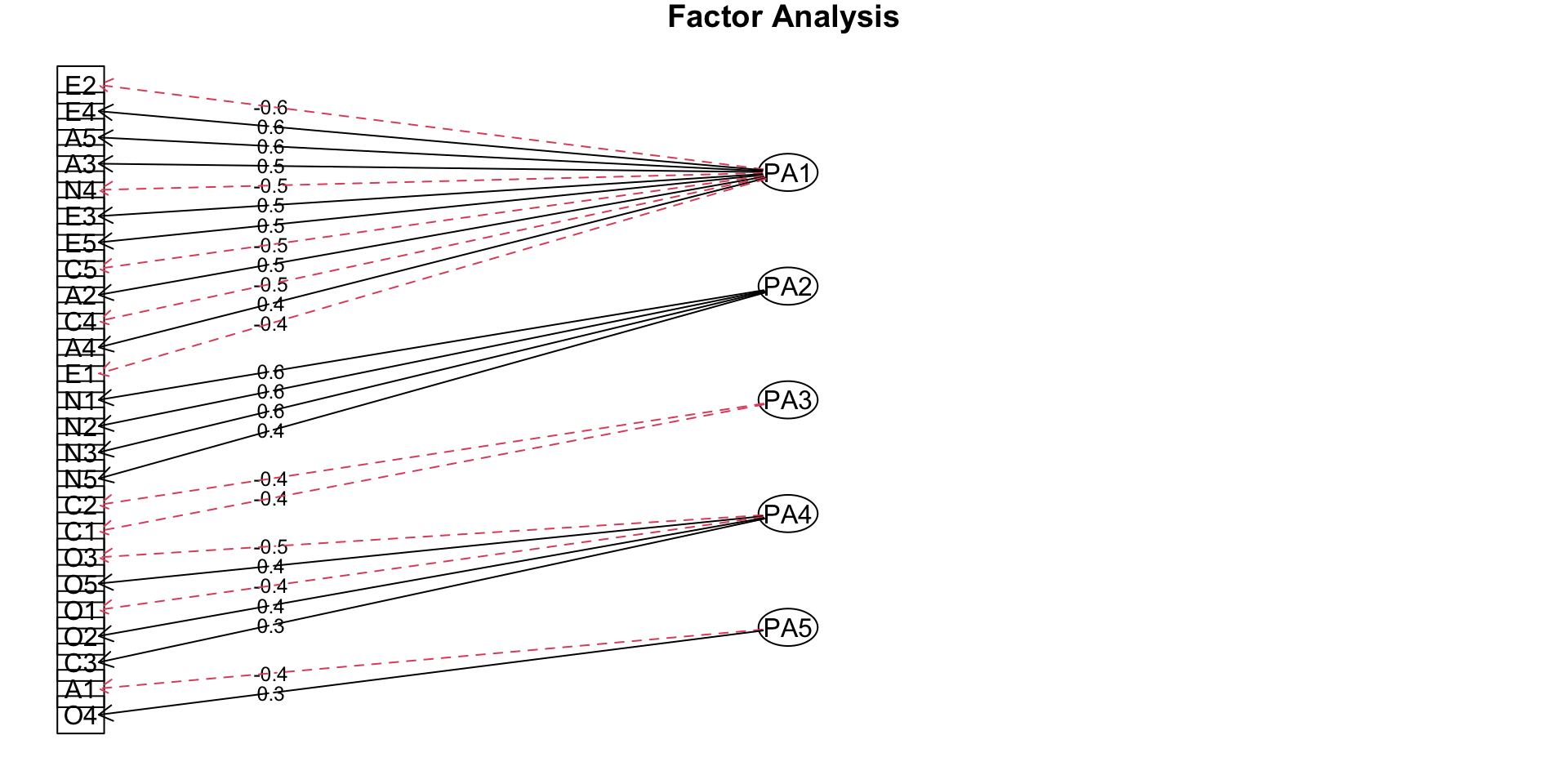
Once the number of factors are decided the researcher runs another factor analysis to get the loading for each of the factors
Principal axis factoring (PAF)
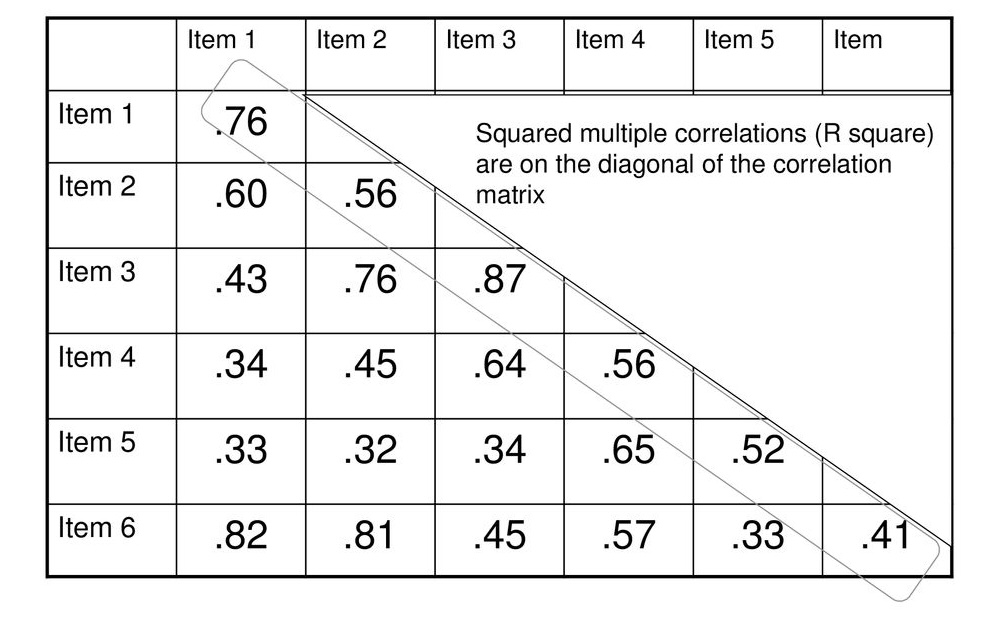
Get initial estimates of communalities
- Squared multiple correlations (highest absolute correlation)
Take correlation matrix and replace diagonal elements with communalities
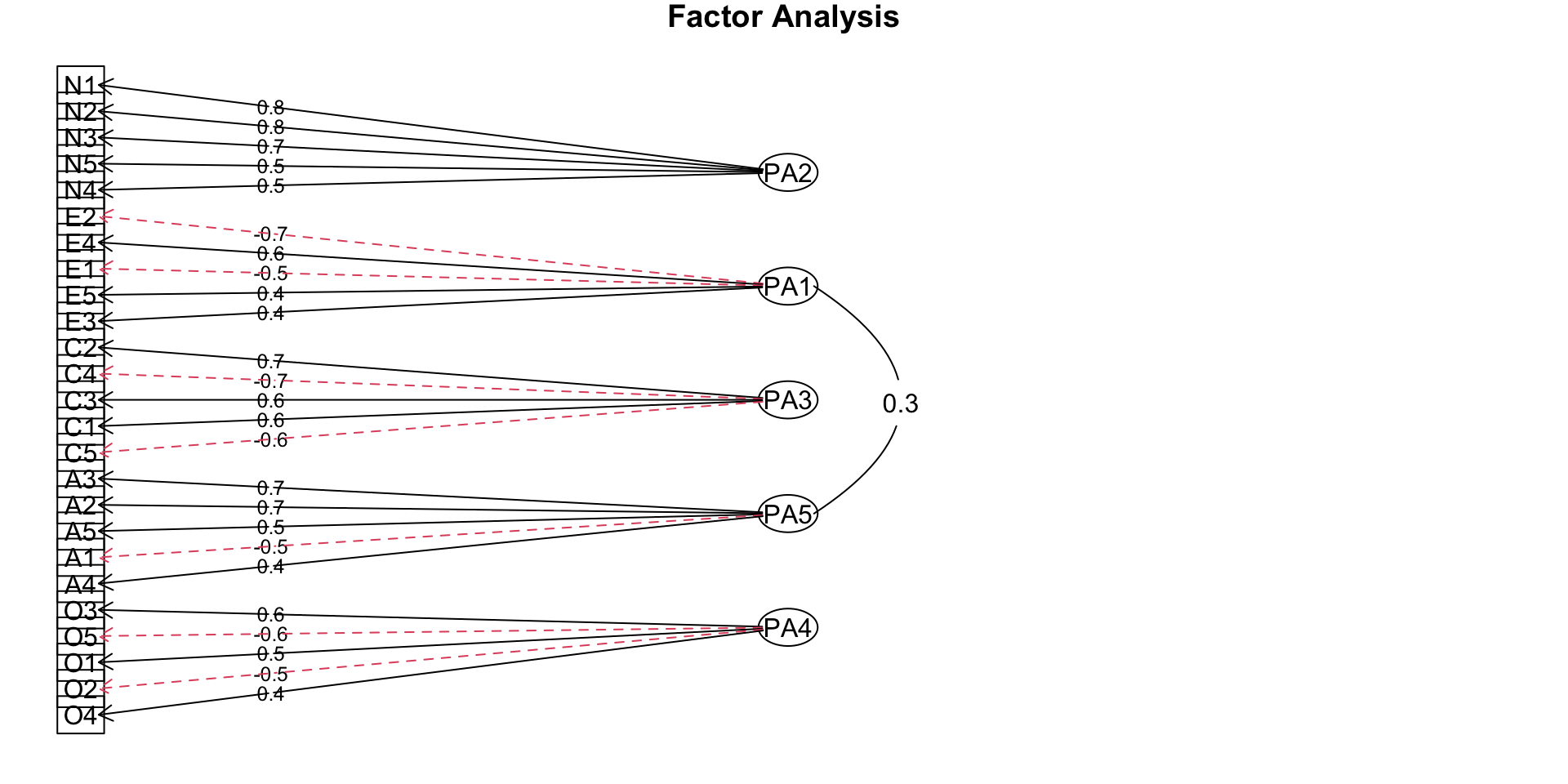
Path diagram
Rotation
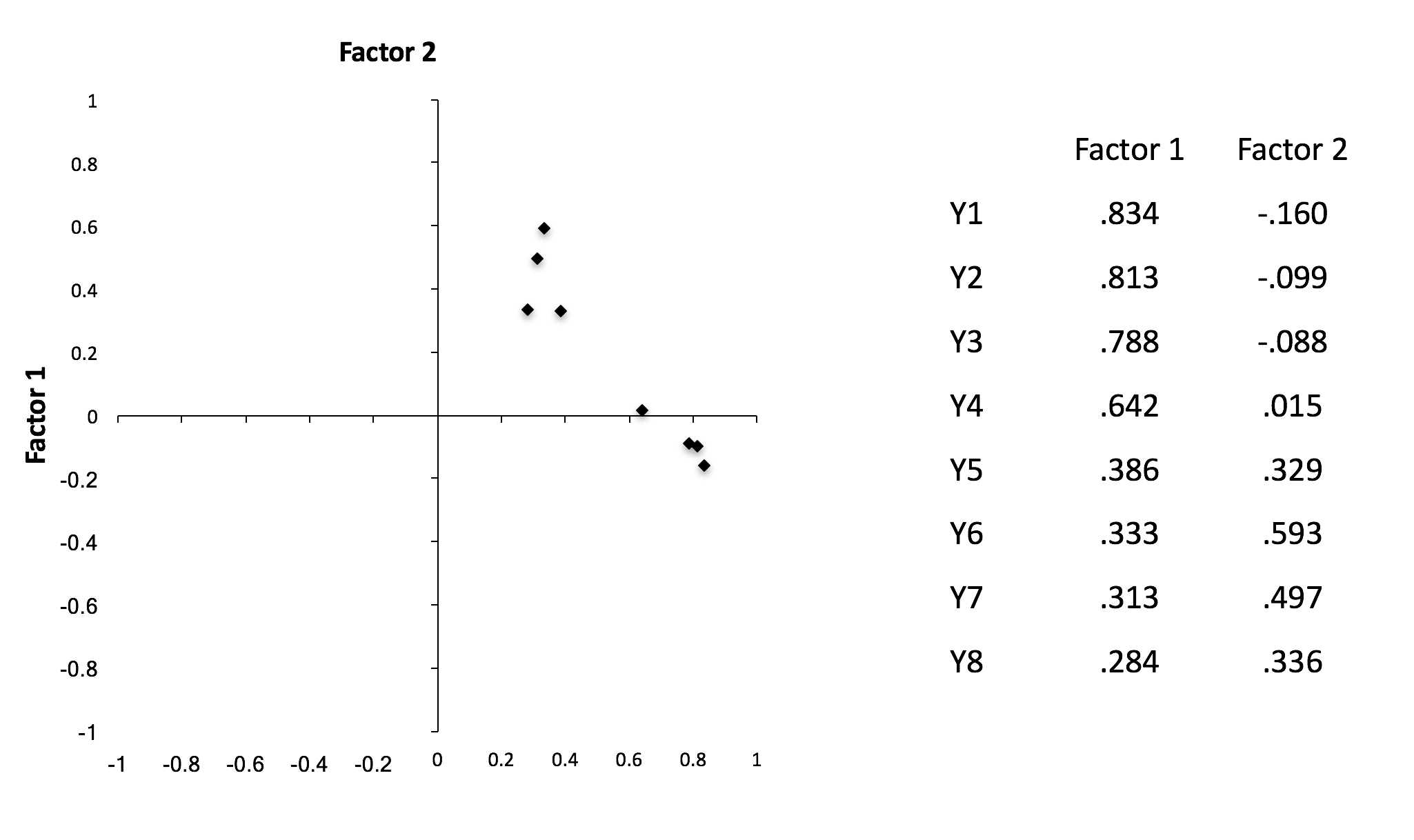
Rotation
- Orthogonal
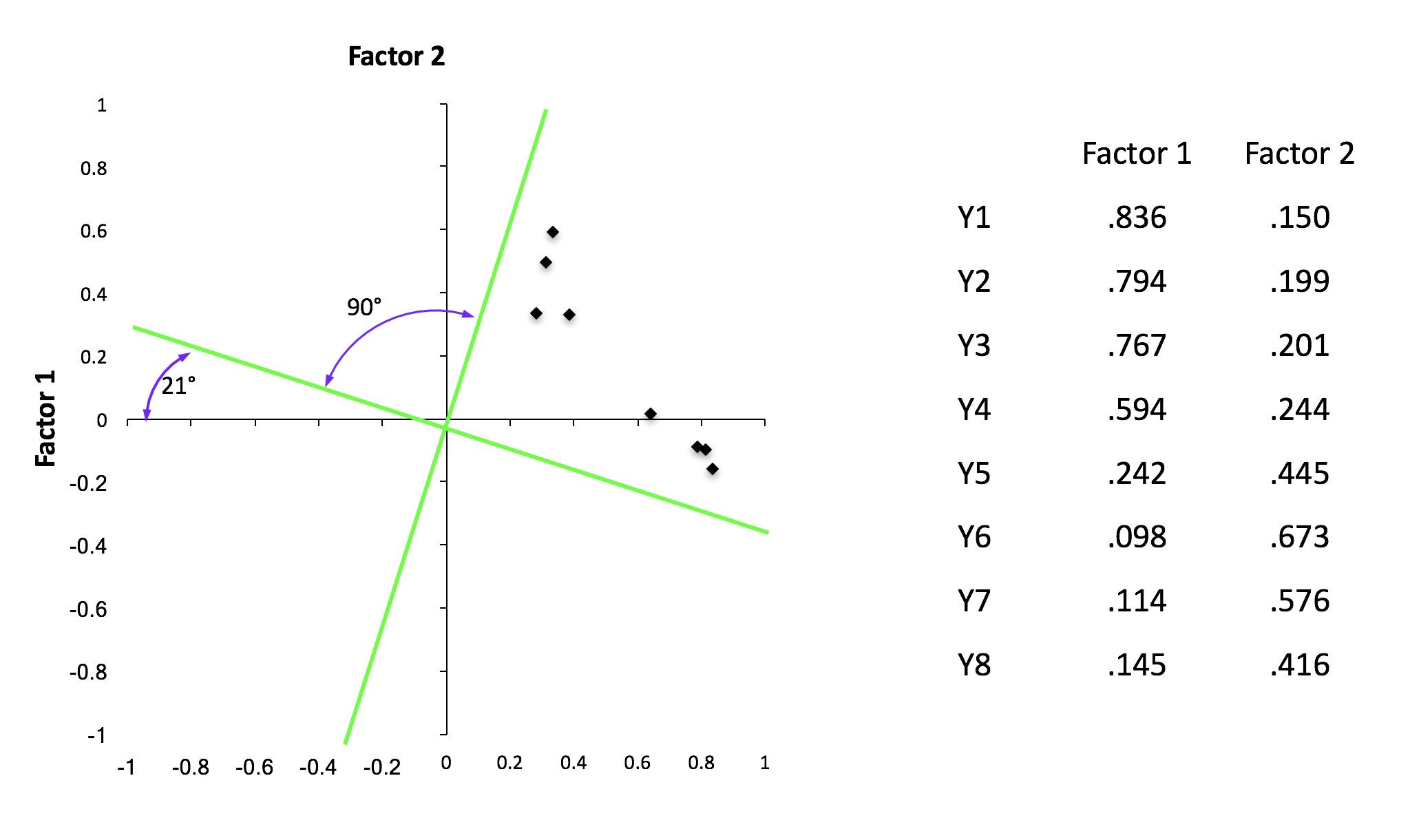
- Oblique
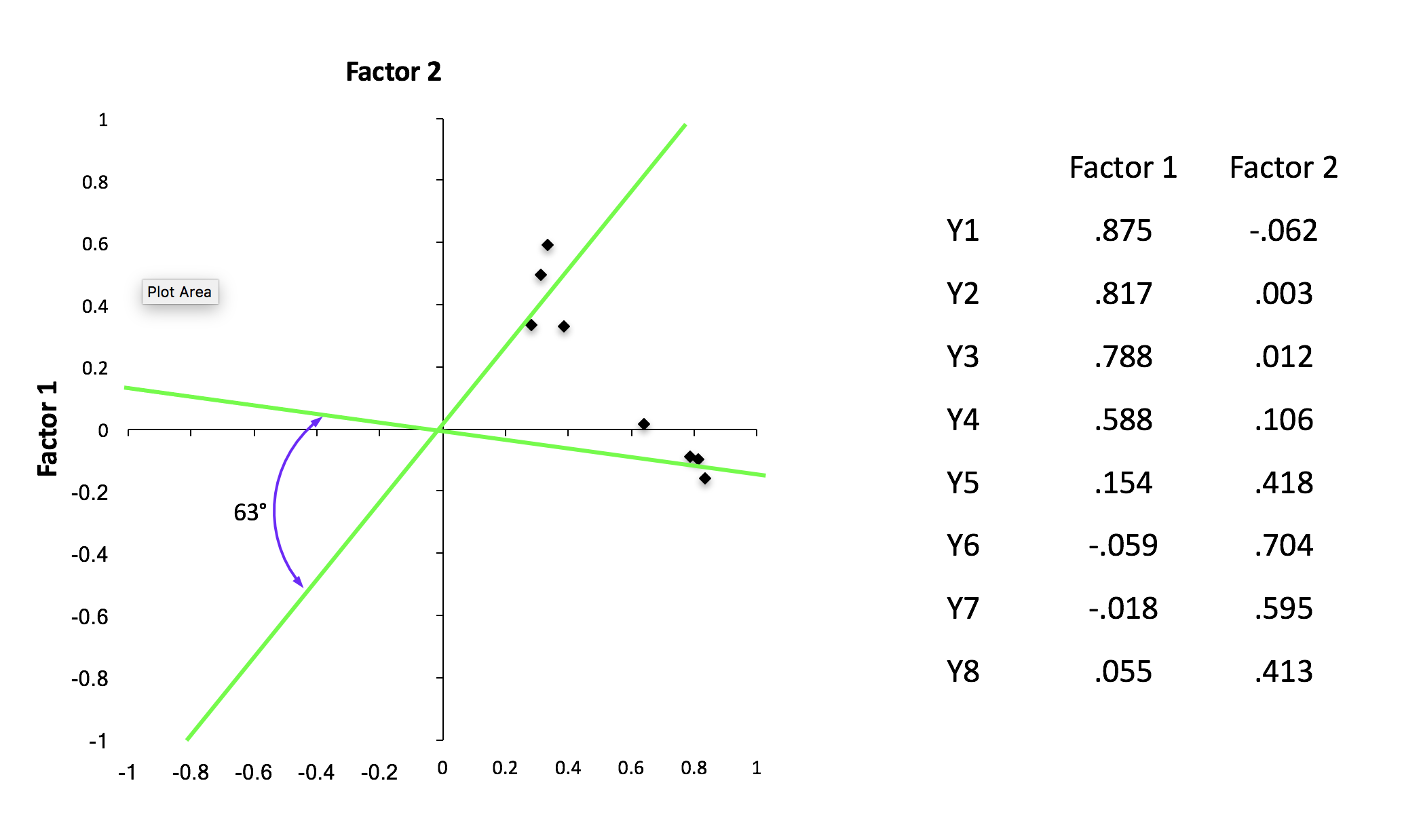
Rotation

Rotation
- After rotation
Factor scores
Geller, J., Thye, M., & Mirman, D. (2019). Estimating effects of graded white matter damage and binary tract disconnection on post-stroke language impairment. NeuroImage, 189. https://doi.org/10.1016/j.neuroimage.2019.01.020
Plotting FA
# correlated rotation
efa_obs <- psych::fa(data, nfactors = 5, rotate="oblimin", fm="pa") %>%
model_parameters(sort = TRUE, threshold = "max")
efa_plot <- as.data.frame(efa_obs) %>%
pivot_longer(PA2:PA4) %>%
dplyr::select(-Complexity, -Uniqueness) %>% rename("Loadings" = value, "Personality" = name)
#For each test, plot the loading as length and fill color of a bar
# note that the length will be the absolute value of the loading but the
# fill color will be the signed value, more on this below
efa_fact_plot <- ggplot(efa_plot, aes(Variable, abs(Loadings), fill=Loadings)) +
facet_wrap(~ Personality, nrow=1) + #place the factors in separate facets
geom_bar(stat="identity") + #make the bars
coord_flip() + #flip the axes so the test names can be horizontal
#define the fill color gradient: blue=positive, red=negative
scale_fill_gradient2(name = "Loading",
high = "blue", mid = "white", low = "red",
midpoint=0, guide=F) +
ylab("Loading Strength") + #improve y-axis label
theme_bw(base_size=12) #use a black-and0white theme with set font size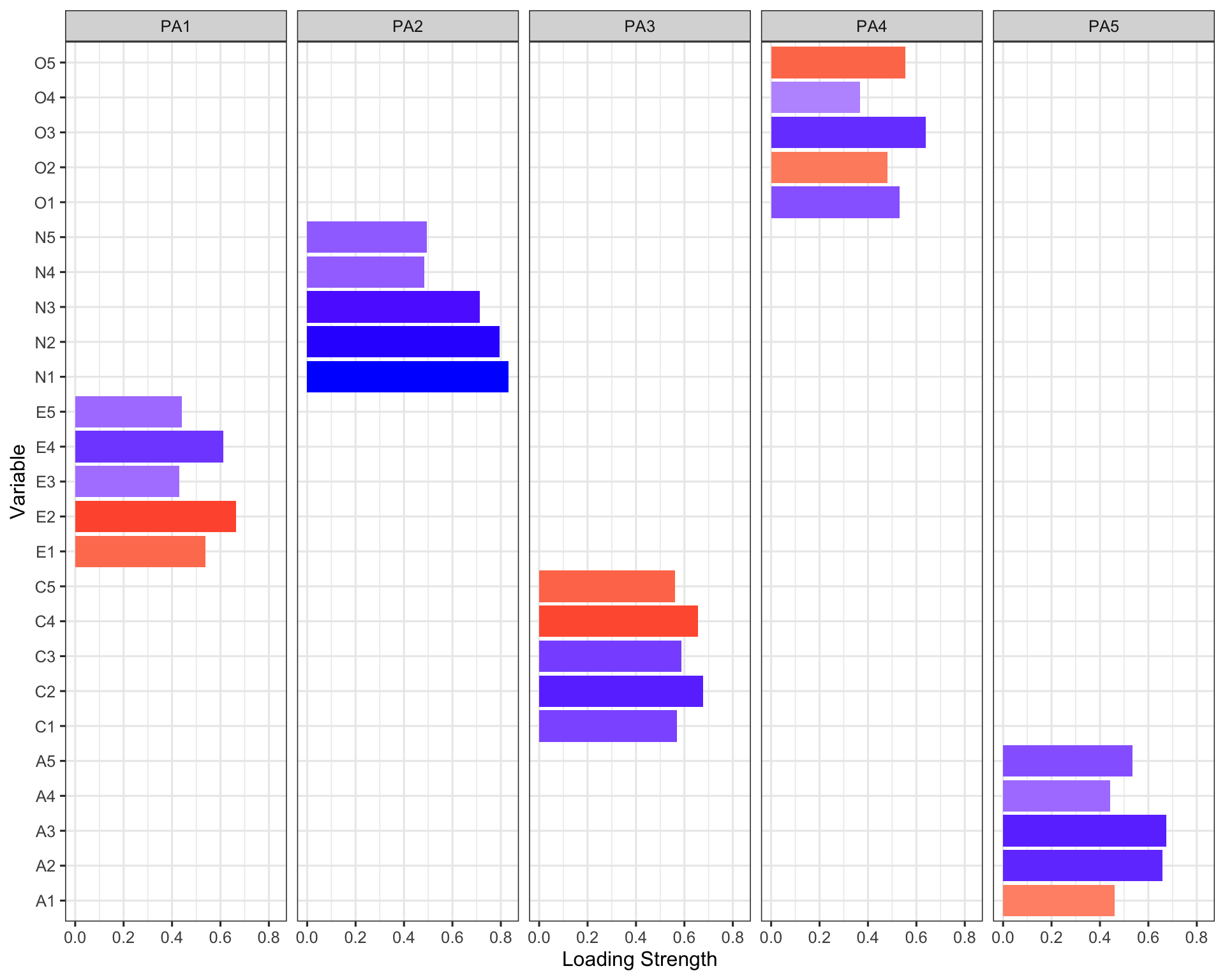
Information to include in paper
