Multilevel Modeing (with R)
Princeton University
4/24/23
Why multilevel modeling?
You might be used to your data looking like this: An independent variable (x) and a dependent variable (y)
![]()
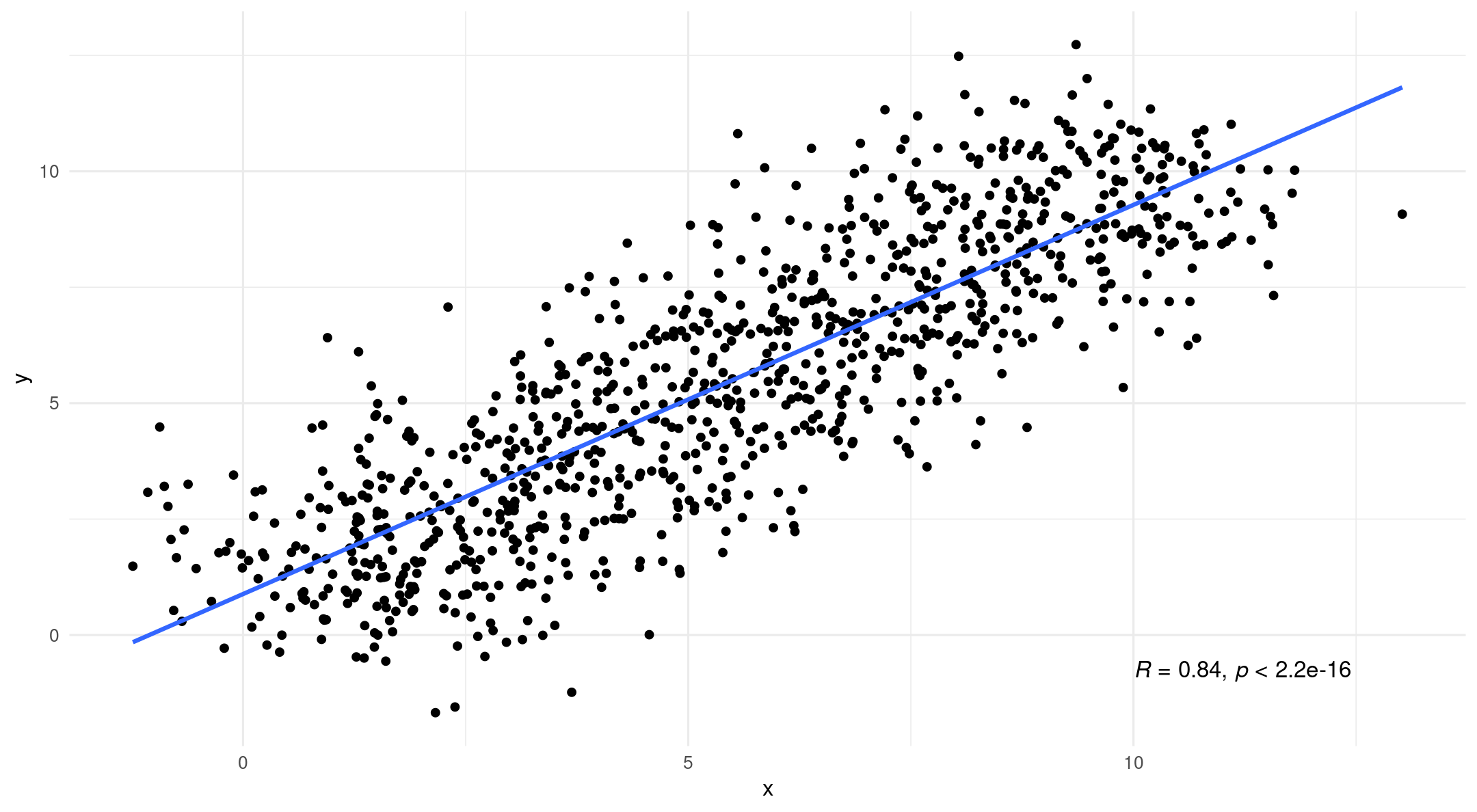
Why multilevel modeling?
- However, if we introduce grouping we tell a different story
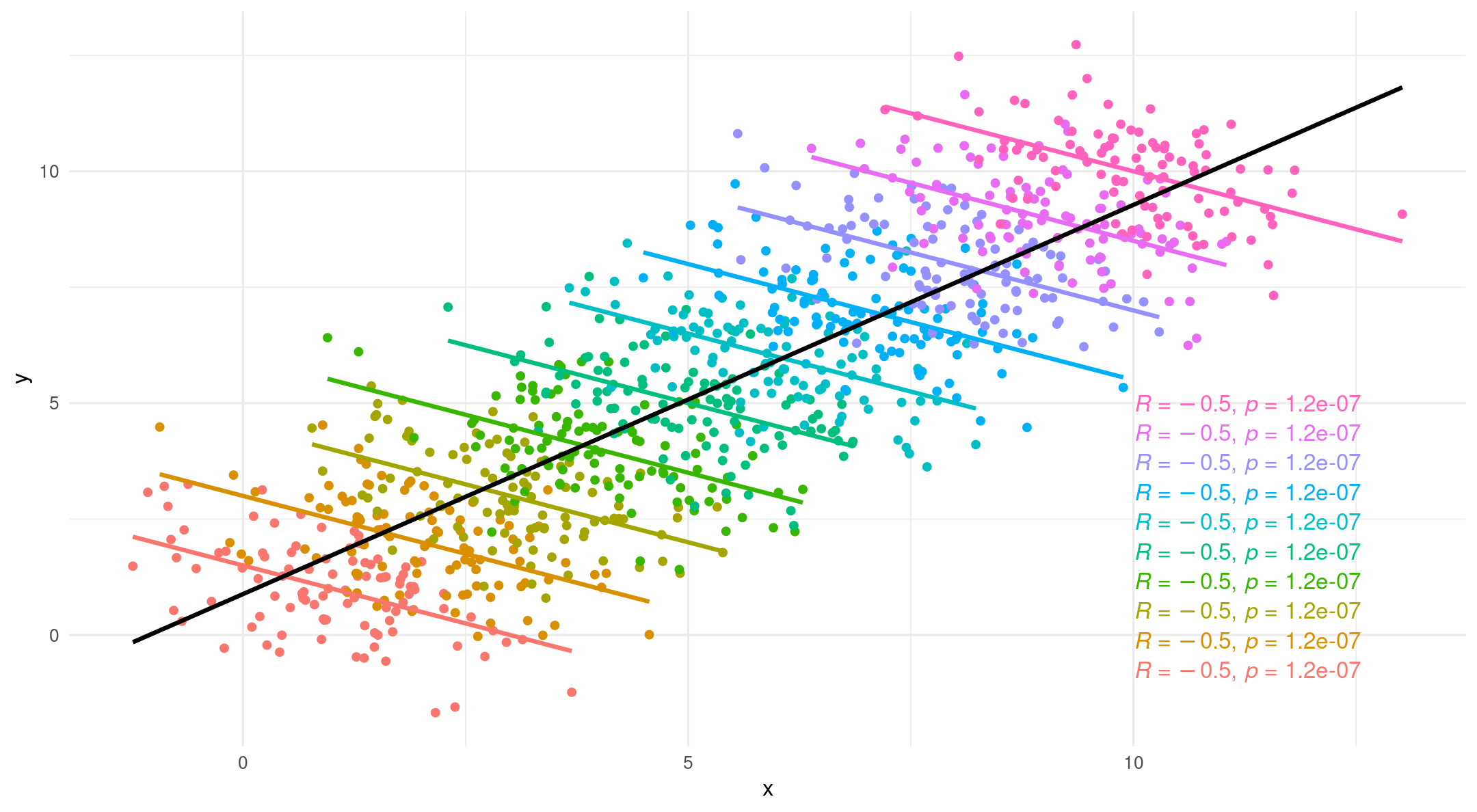
What is multilevel modeling?
- Simpson’s Paradox

What is multilevel modeling?

What is multilevel modeling?
- An elaboration on regression to deal with non-independence between data points (i.e., clustered data)
Hierarchies
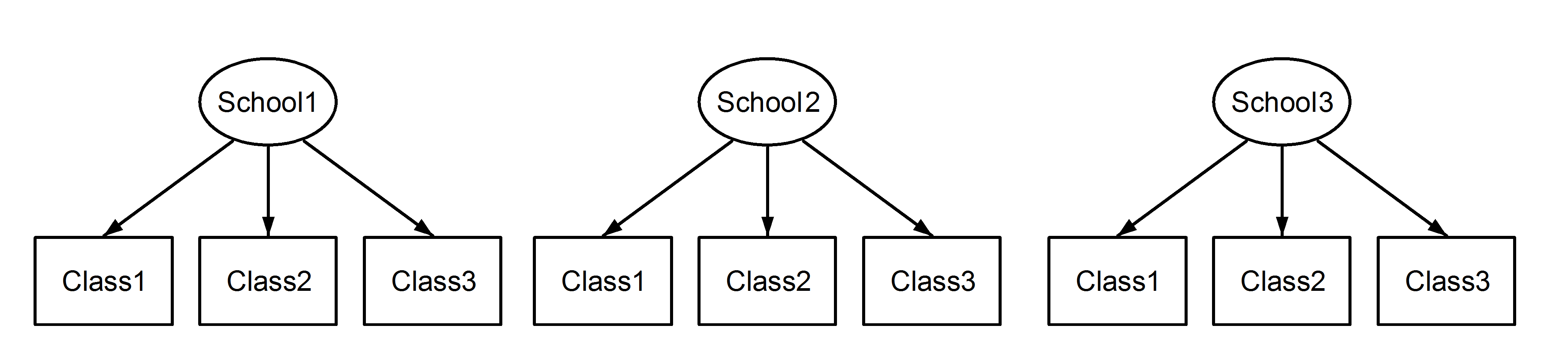
- For now we will focus on data with two levels:
- Level one: most basic level of observation
- Level two: groups formed from aggregated level-one observation
Multilevel models are awesome!
- Interdependence
- You can model the relationships between cases (regression for repeated observations)
- Missing data
- Uses ML for missing data (partial pooling or shrinkage)
- Power
- Deaggregated data
- Take into account within and between variance
- Flexibility

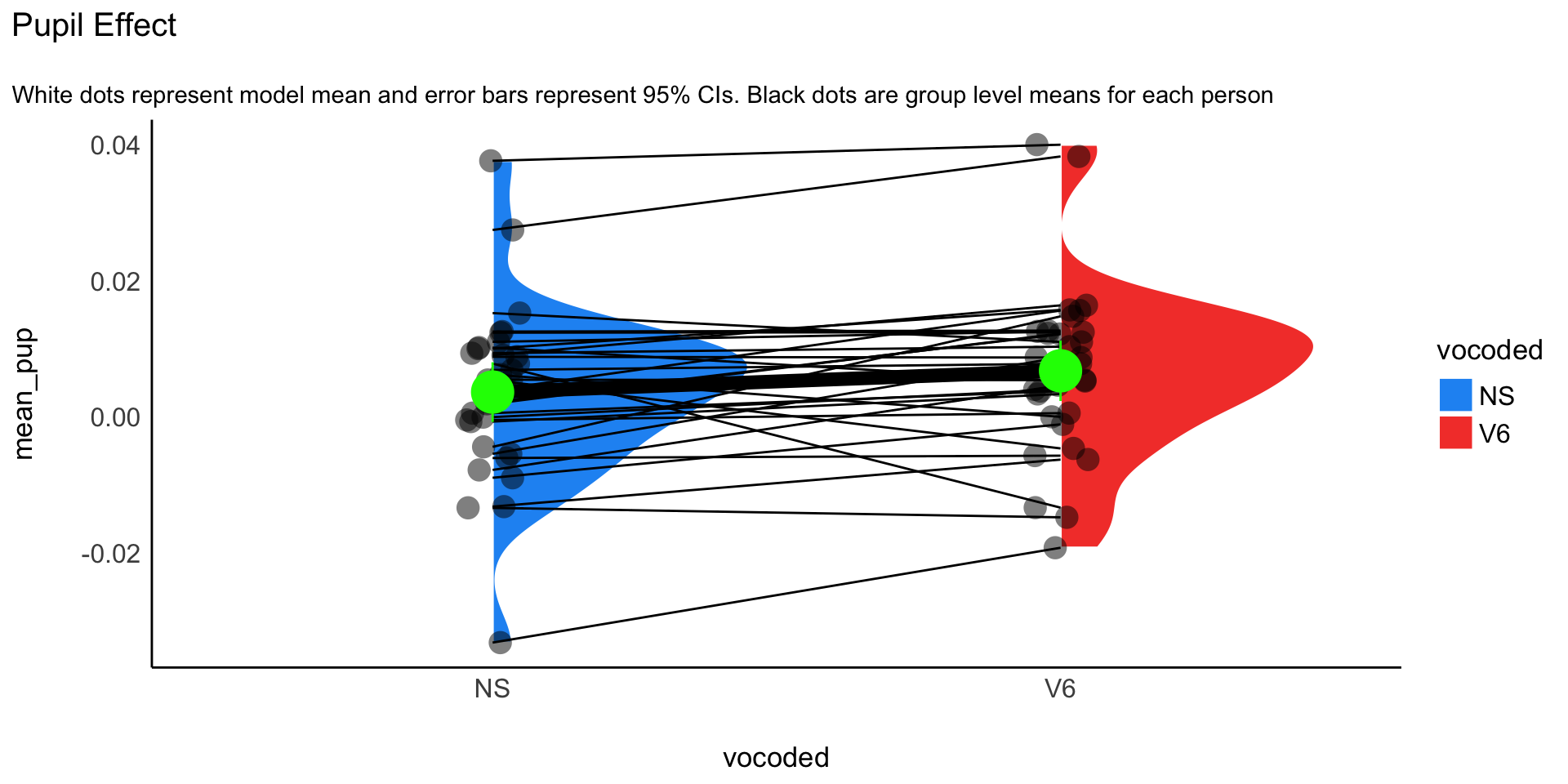
Today’s data
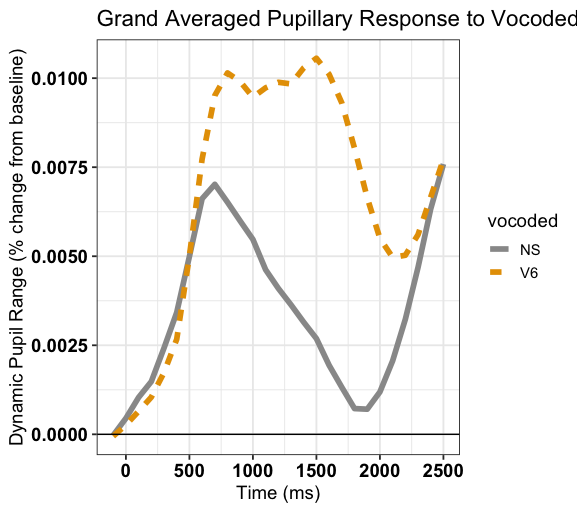
What did you say?
- Ps (N = 31) listened to clear (NS) and 6 channel vocoded speech (V6)
- (https://www.mrc-cbu.cam.ac.uk/personal/matt.davis/vocode/a1_6.wav)
- Ps (N = 31) listened to clear (NS) and 6 channel vocoded speech (V6)
Data
library(tidyverse)
library(lme4) # fit mixed models
library(broom.mixed) # tidy output of mixed models
library(afex) # fit mixed models
library(emmeans) # marginal means
library(ggeffects) # marginal means
eye <- read_csv("https://raw.githubusercontent.com/jgeller112/psy504-advanced-stats/main/slides/MLM/data/vocoded_pupil.csv")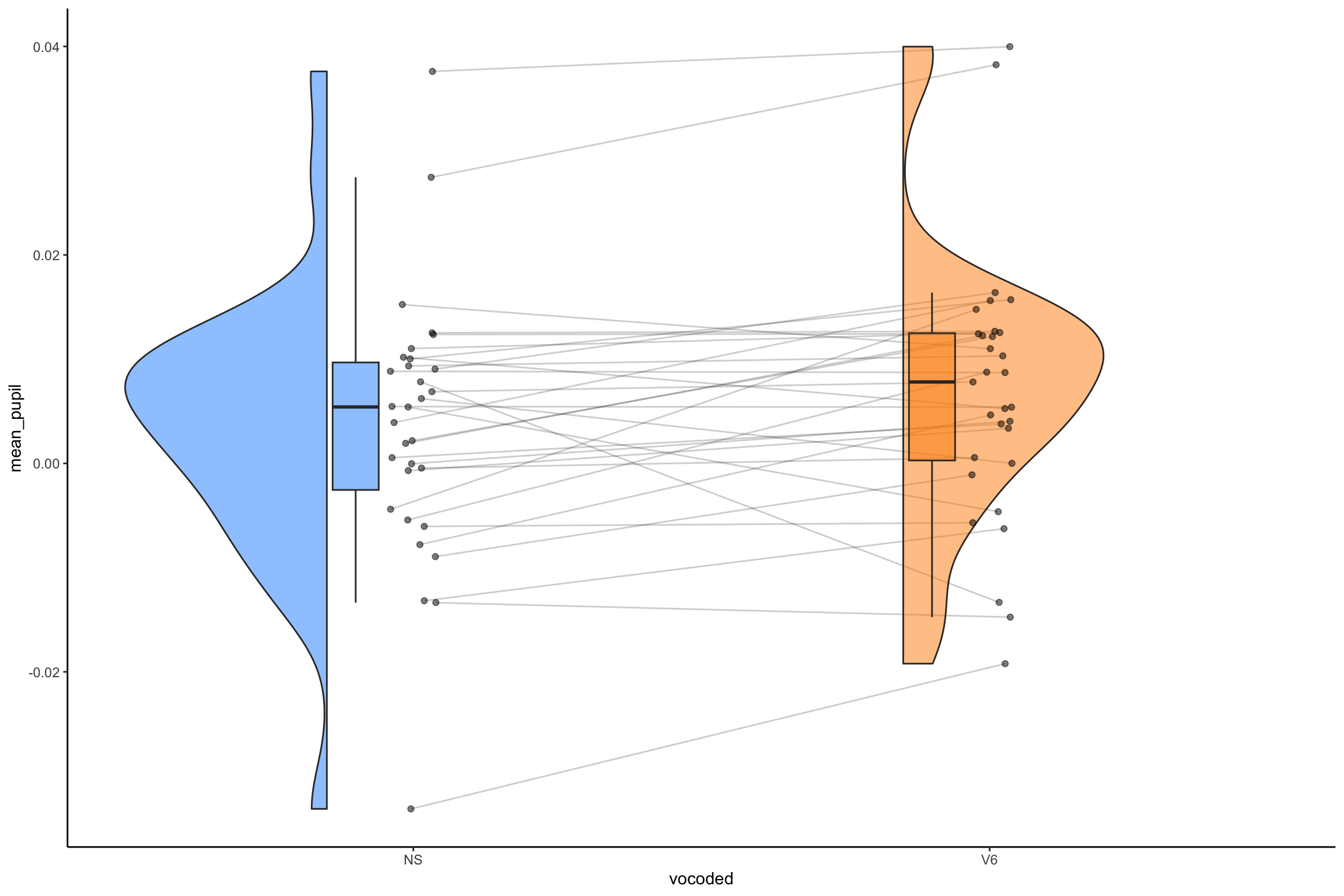
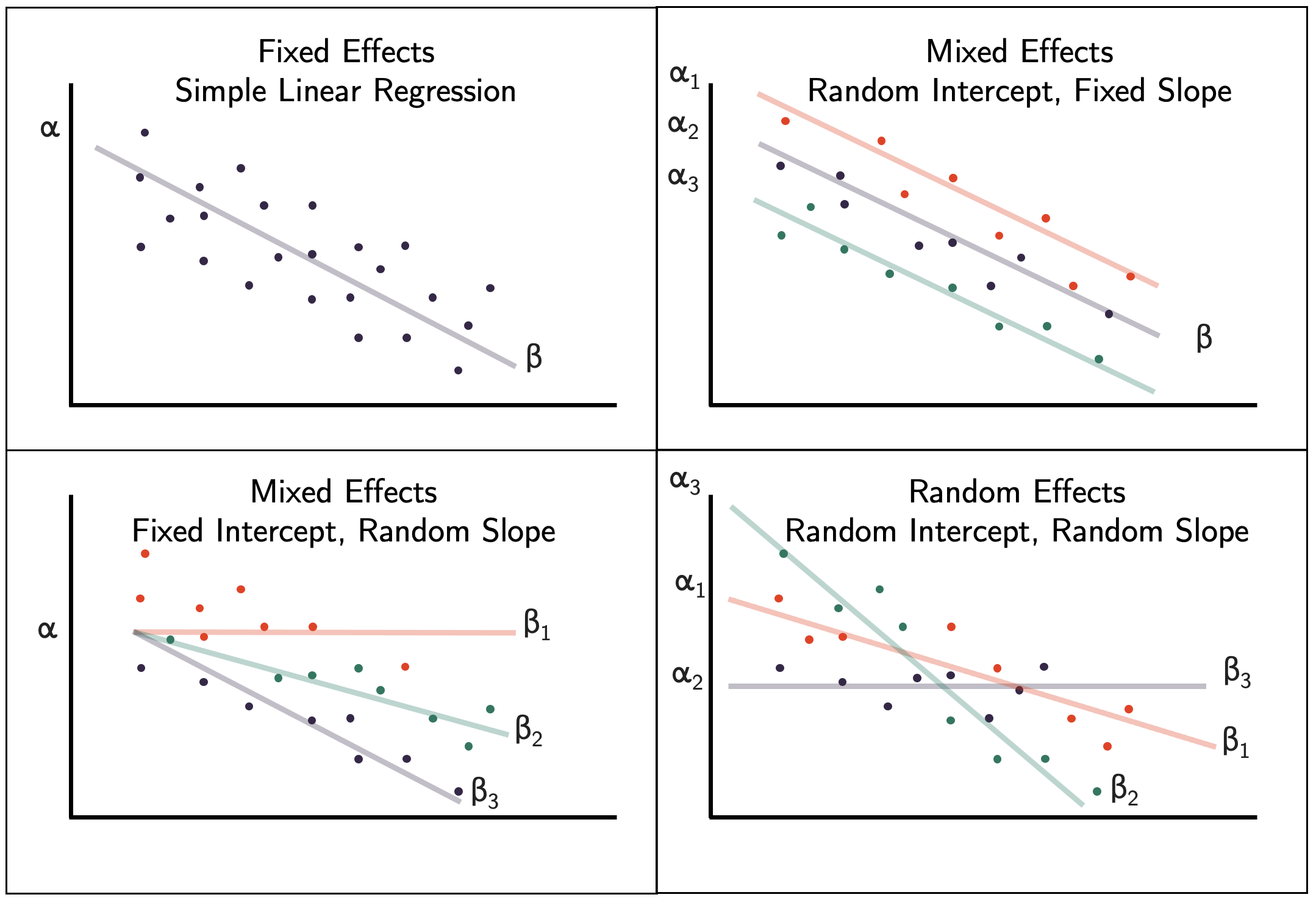
Random intercepts
Varying starting point (intercept), same slope for each group
(1|participant): random intercept for group
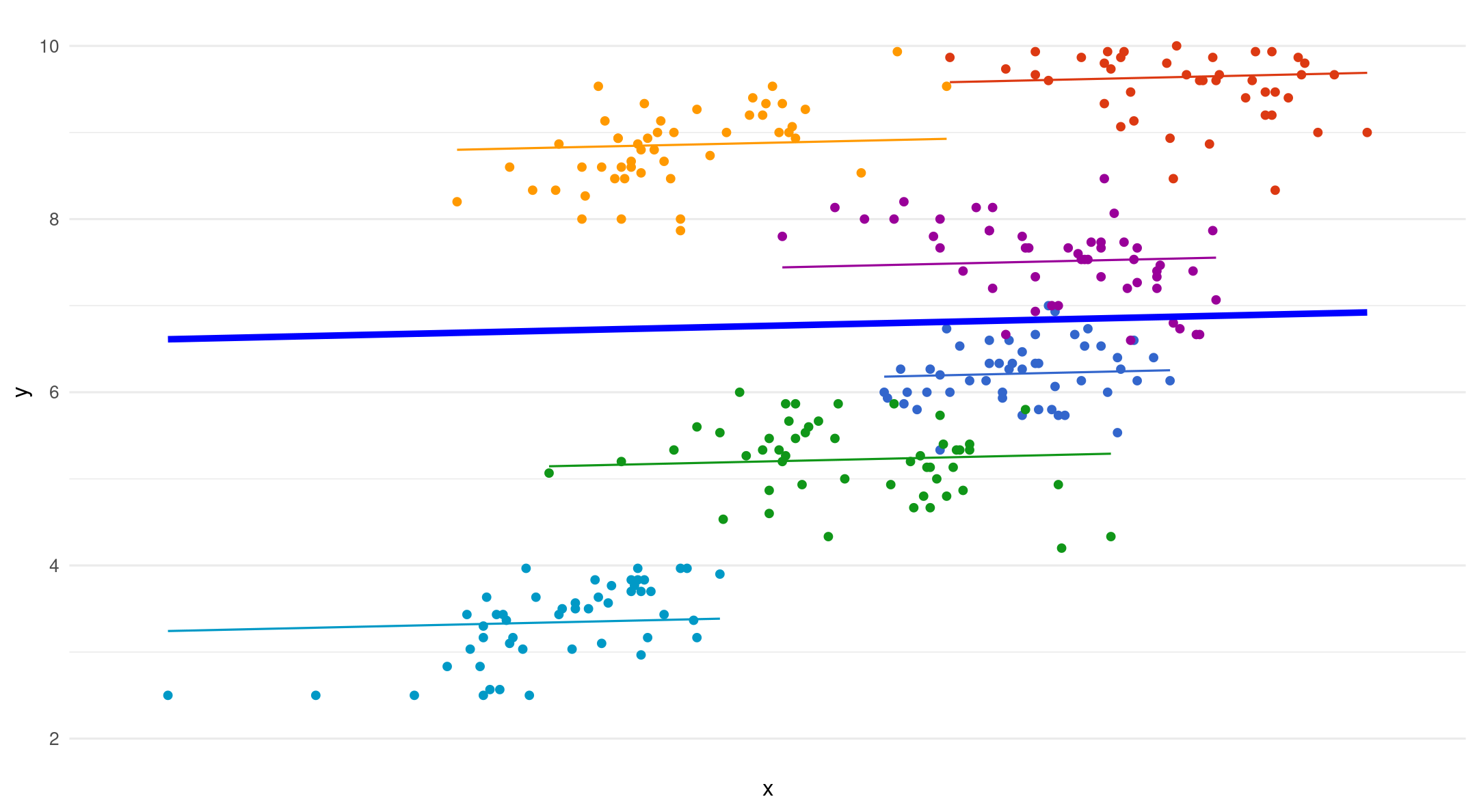
Random intercepts
In a multilevel model, error terms for individual data points are estimated by group
Person-specific deviation from group’s predicted outcome
\[ y_{ij} = (\beta_{0} + u_{0j}) \]
Random intercepts - fixed slopes
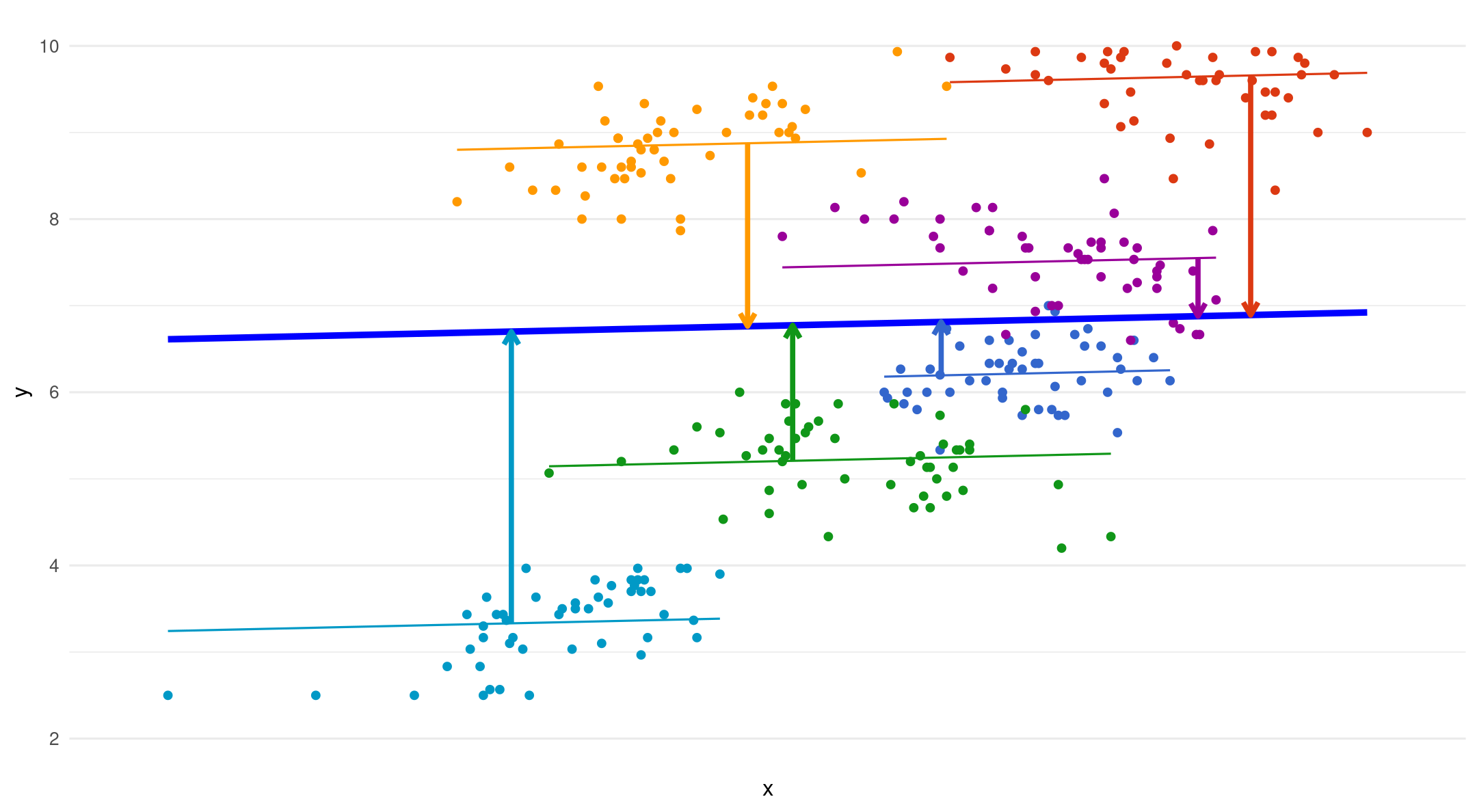
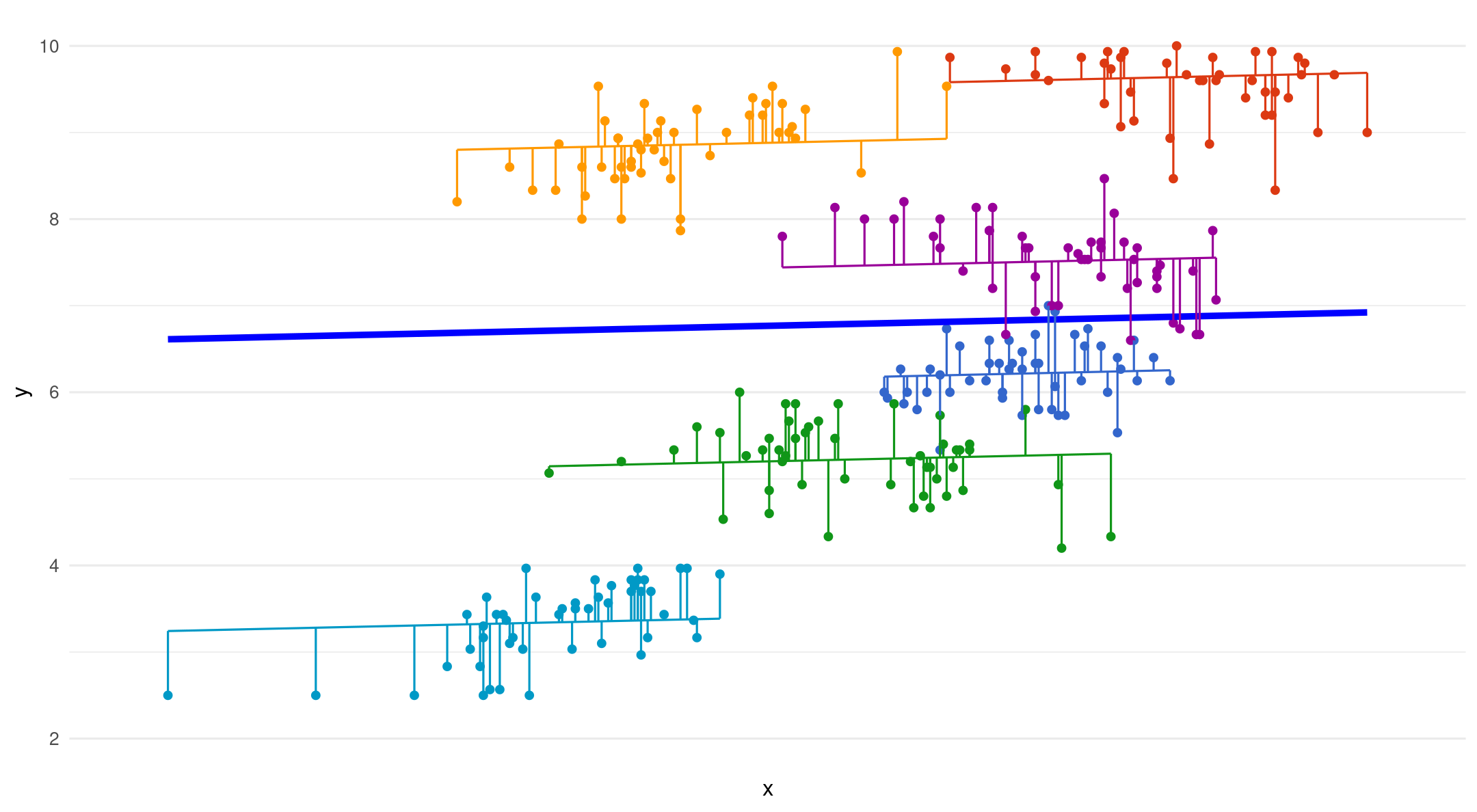
Random intercepts - random slopes
Varying starting point (intercept) and slope per group
(1+vocoded|group): random intercept and slopes per group
Only put a random slope if it changes within cluster/group
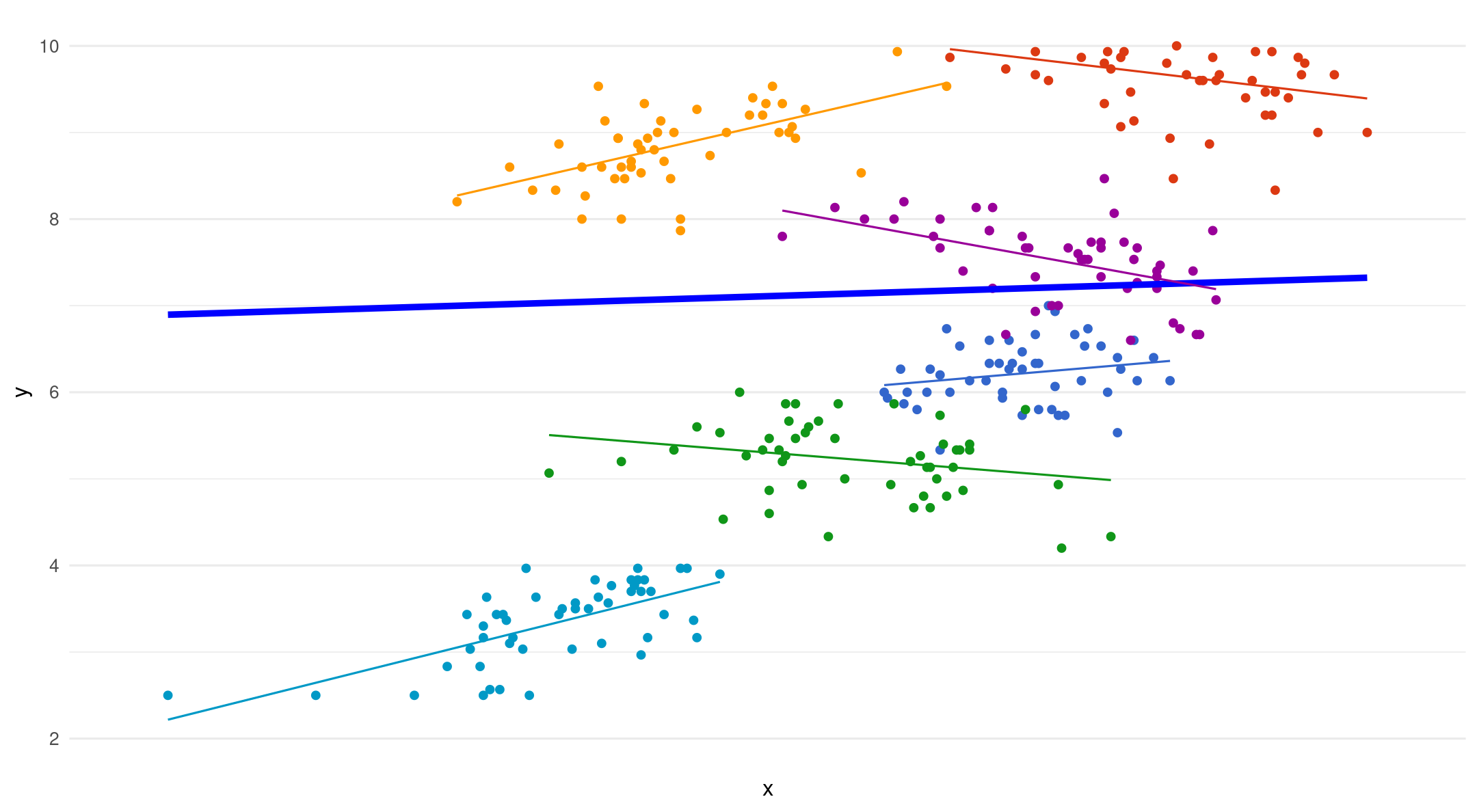
Random intercepts - random slope
- The dotted lines are fixed slopes. The arrows show the added error term for each random slope
\[ y_{ij}=(\beta_{1} + u_{1j}) \]
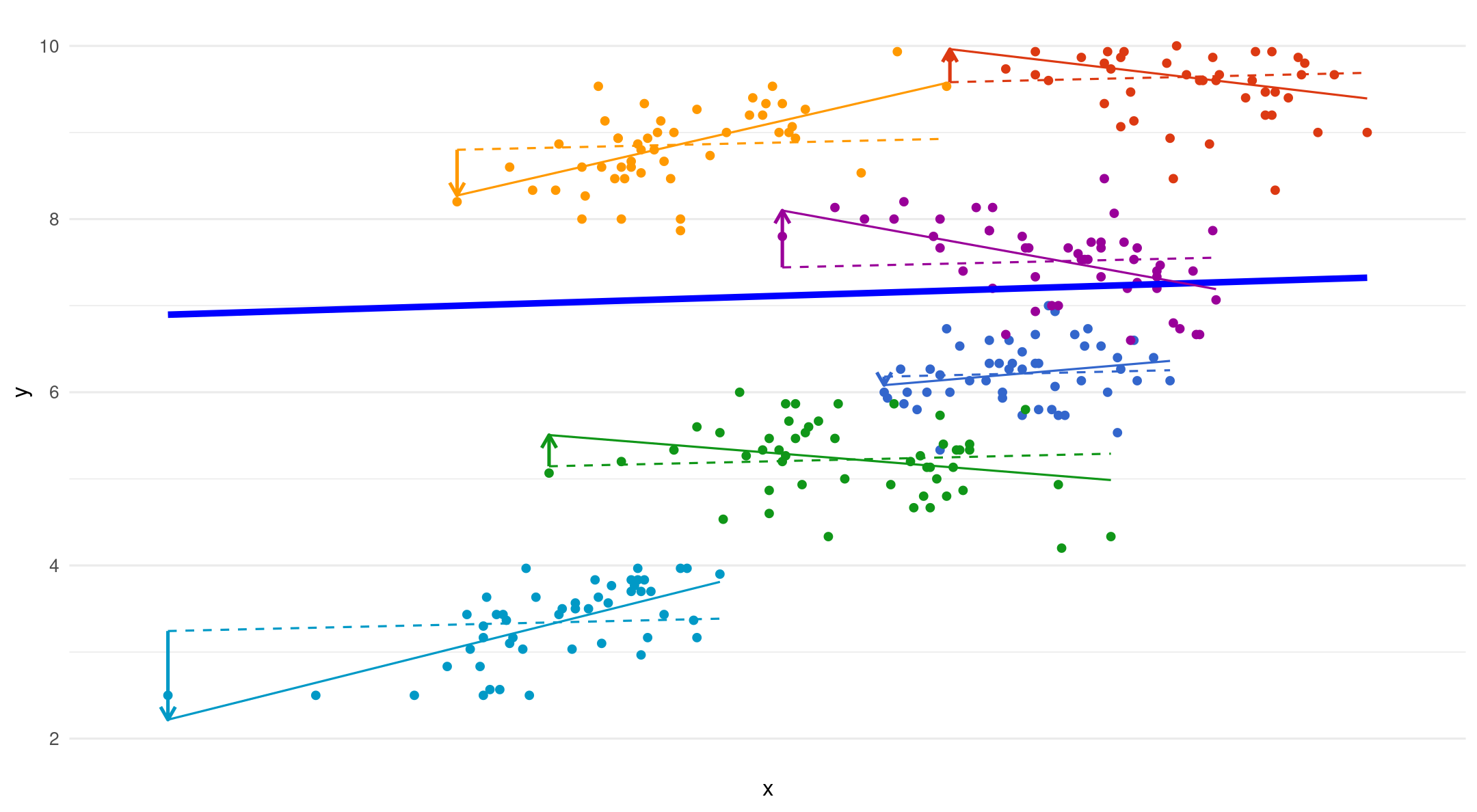
All together
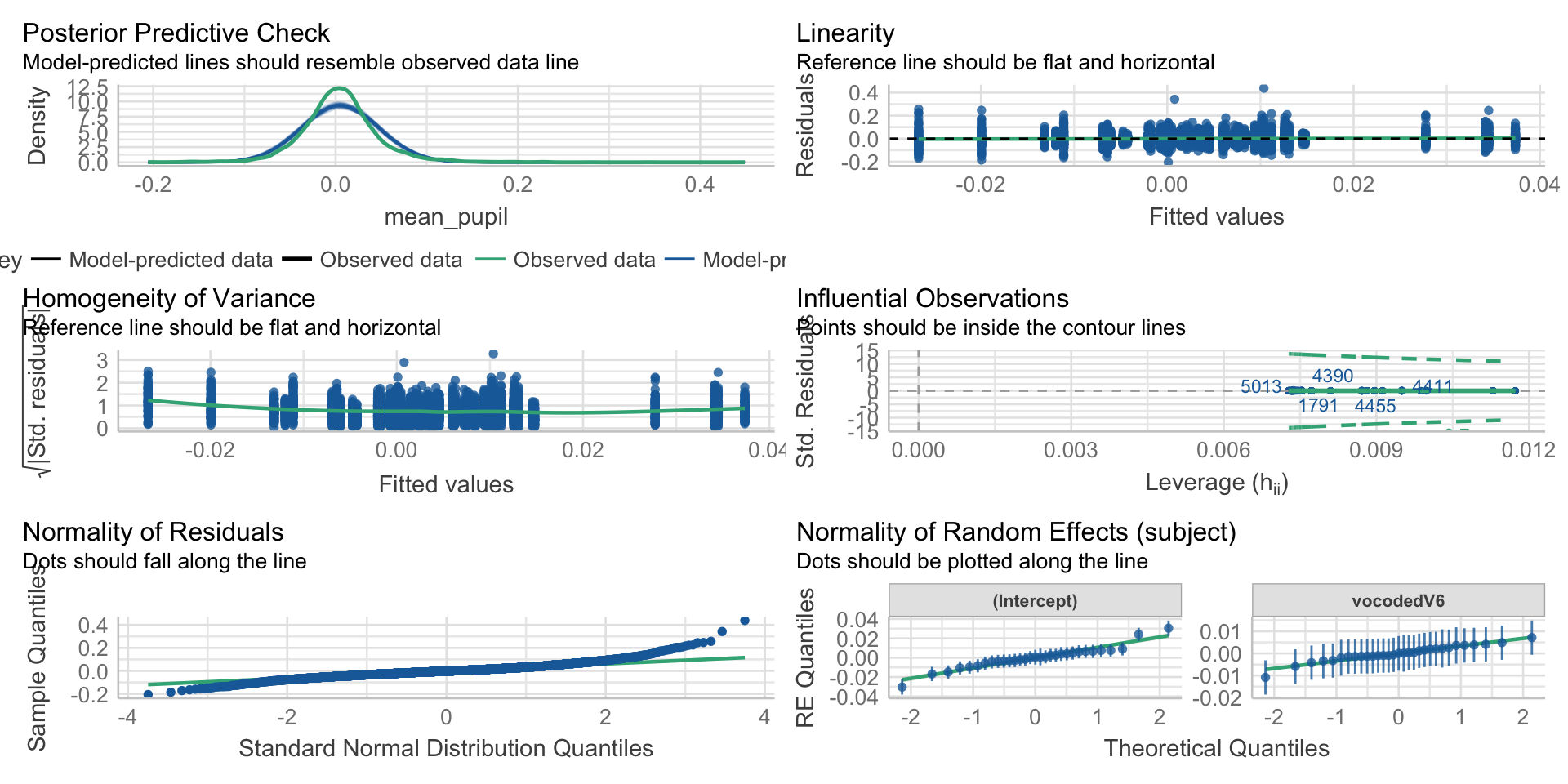
Check assumptions
Linearity
Normality
Homoscedasticity
Collinearity
Outliers
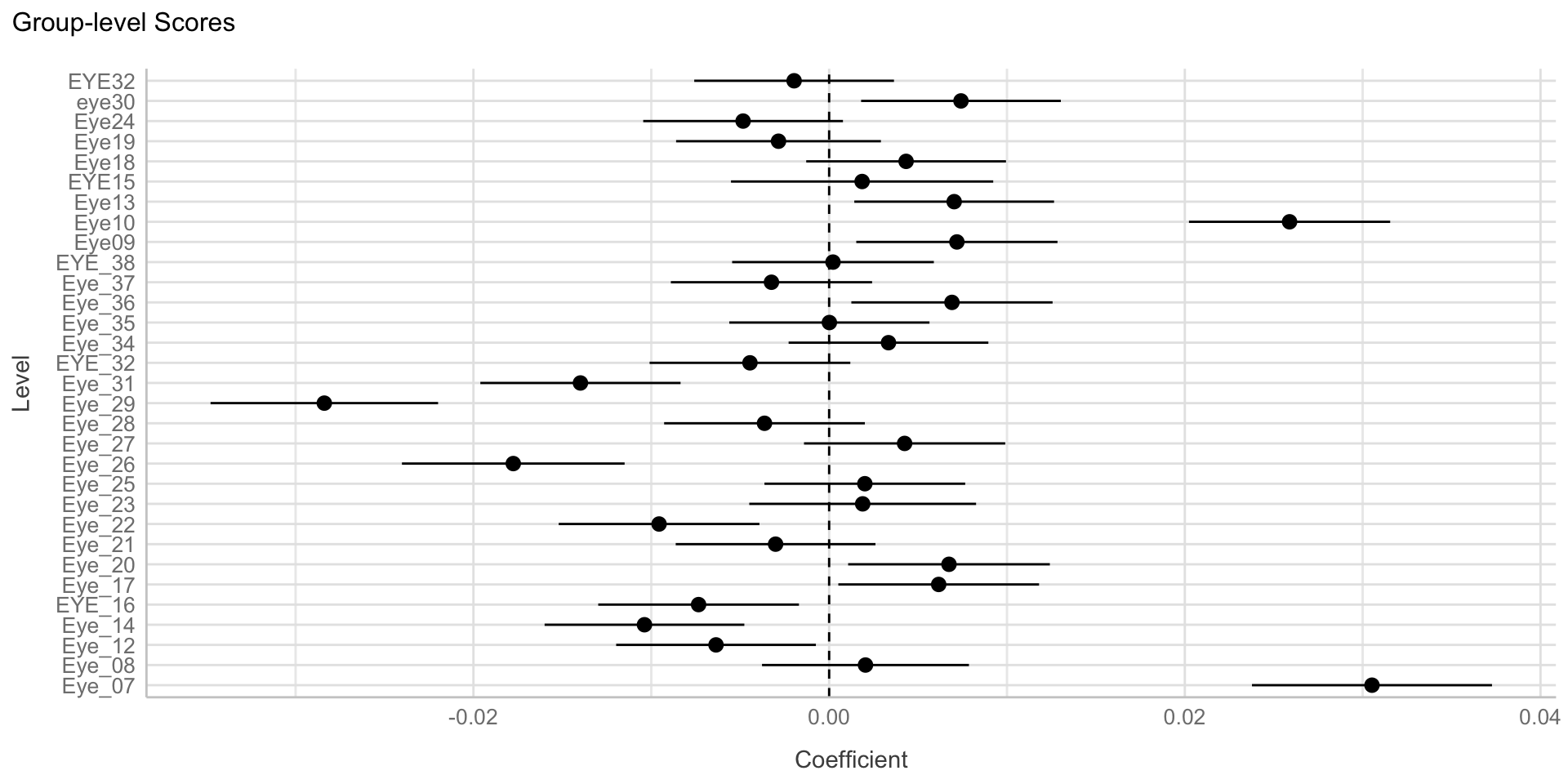
Visualize random effects
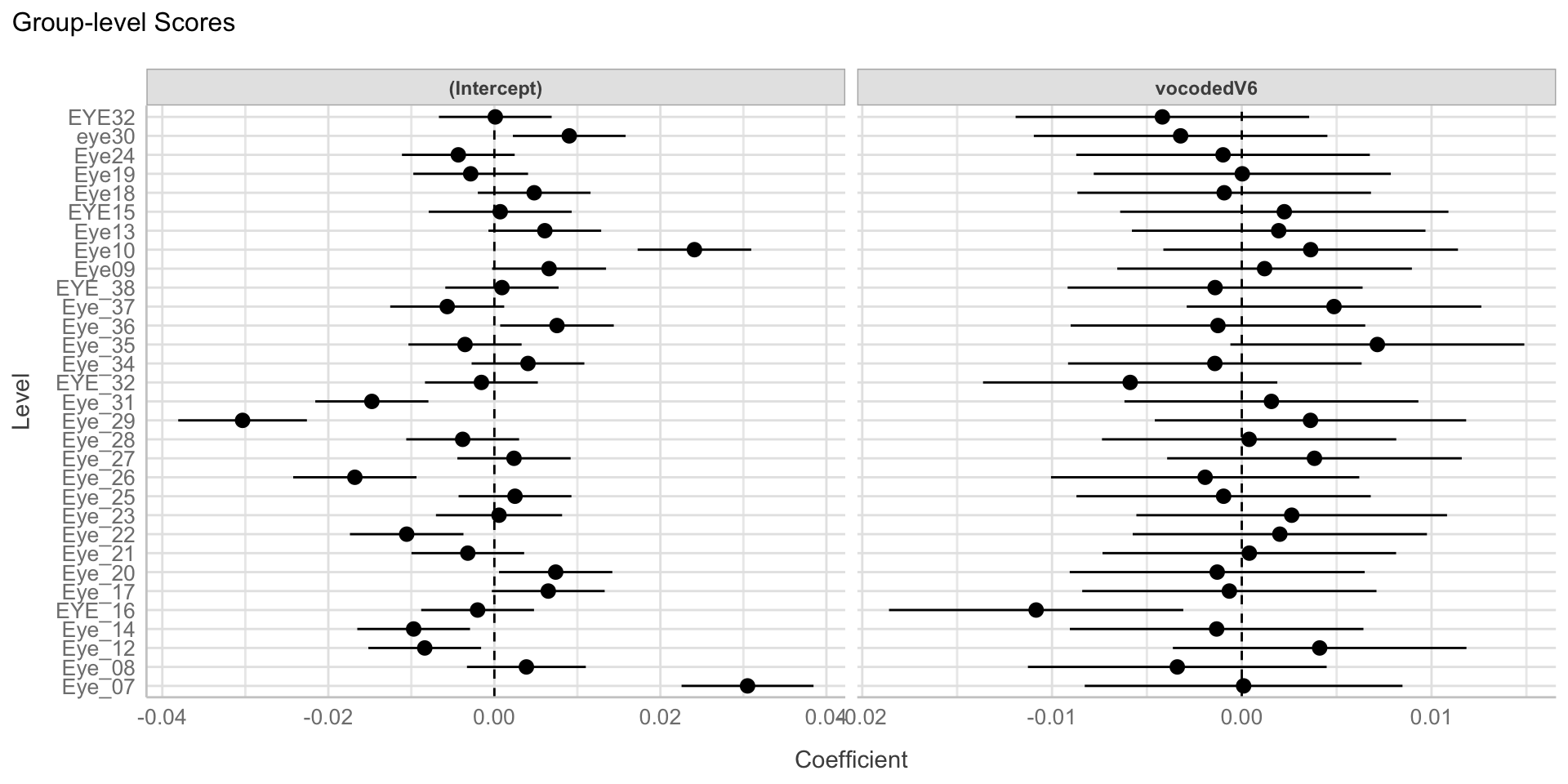
Visualize random intercepts + slopes
Random effects/variance components
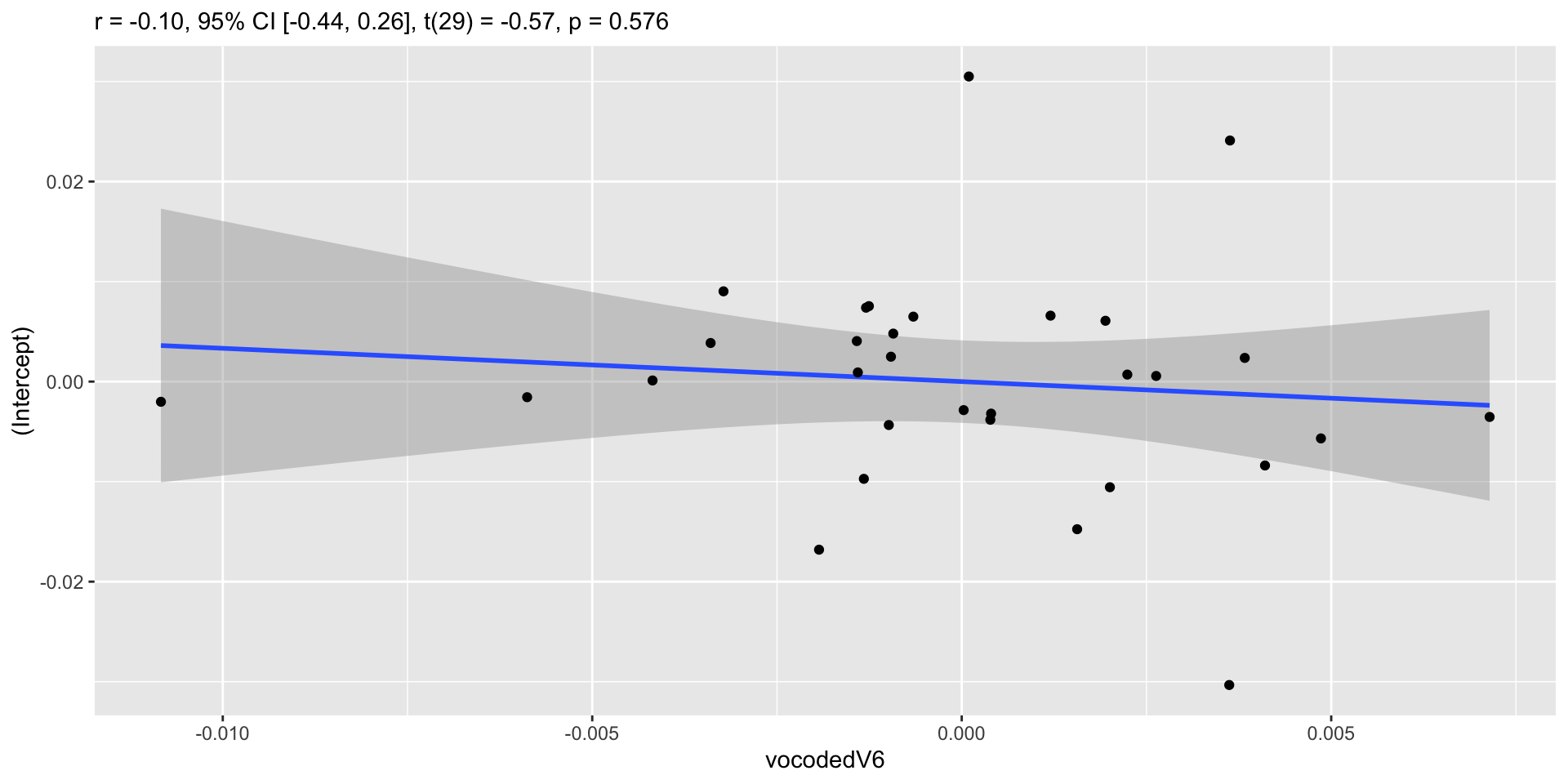
Correlation between random intercepts and slopes
Negative correlation
- Higher intercept (for normal speech) less of effect (lower slope)
Easystats
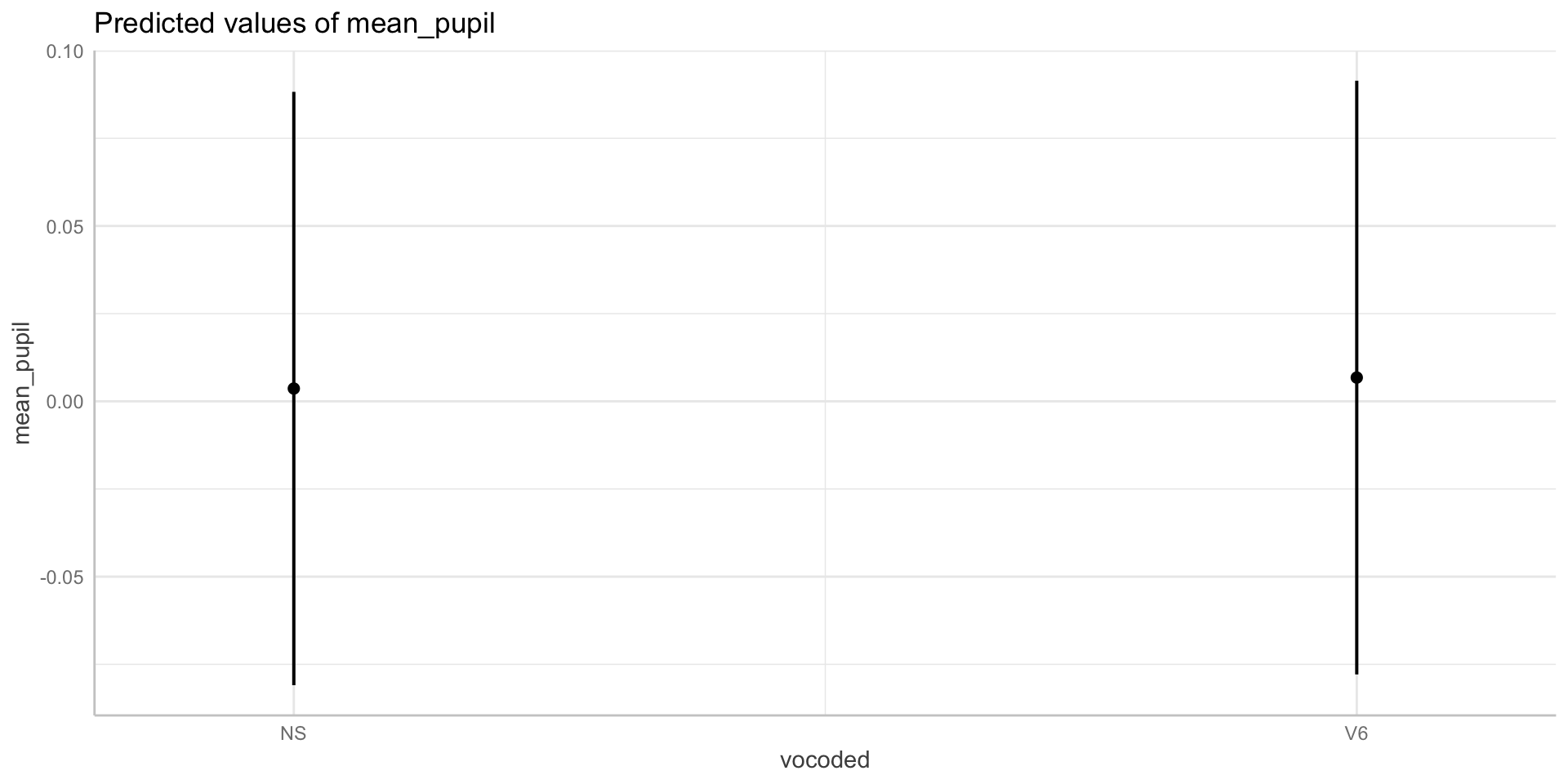
ggeffects
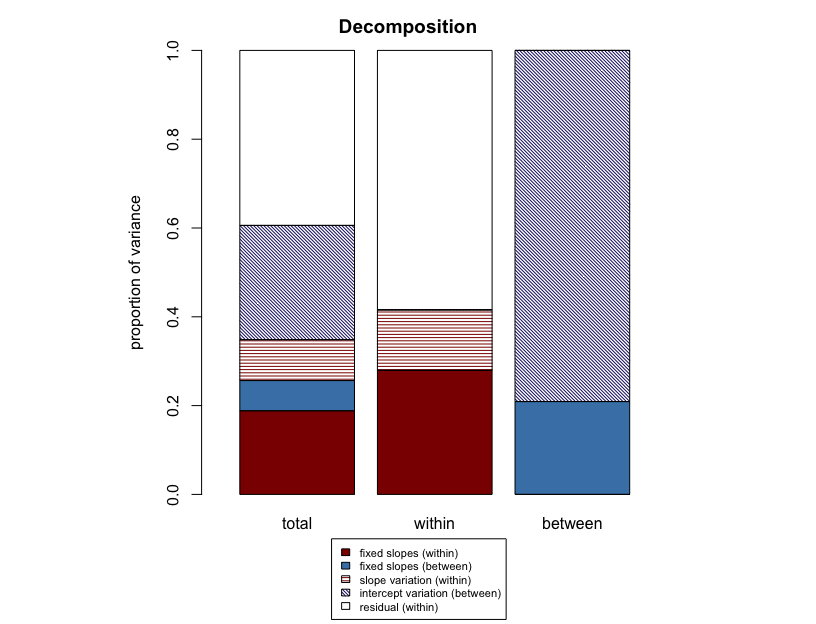
r2mlm
Shrinkage
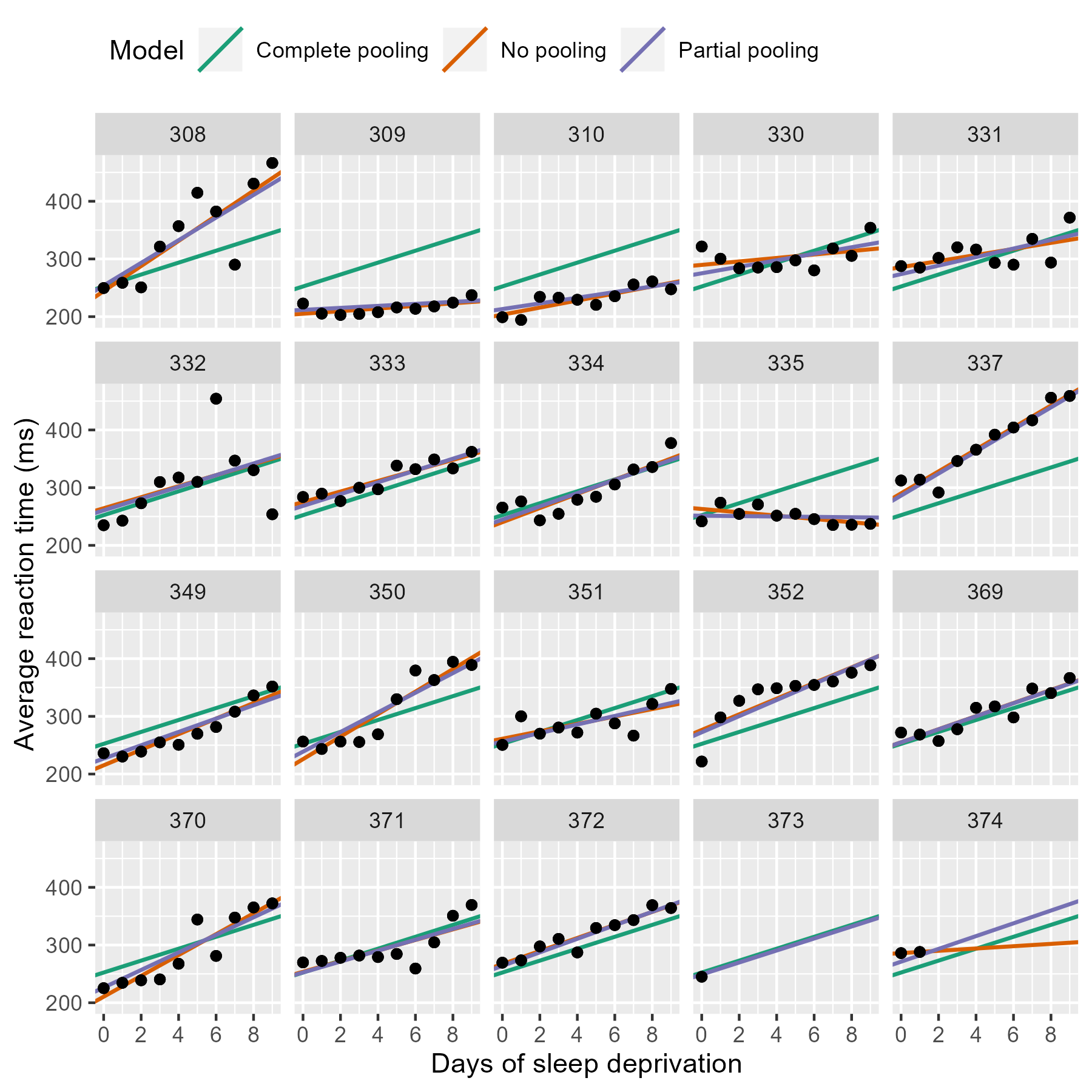
(https://www.tjmahr.com/plotting-partial-pooling-in-mixed-effects-models/)